请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:
- 所在小组:第一组
- 组内昵称:加油
- 你的心得体会(可以是基于不同知识点进行,但是每人每周都只发一个帖子)
- 一段自己的阐述
- 第二-N段自己的阐述
请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:

计算机表示和保存数据,实际是由0或1的位(bit)组成,8位为一个字节(byte),程序源代码本质上也是一个个byte组成。
书中的hello.c全部由ascii字符组成,ascii字符集中的字符由一个字表示(0到127),共128个字符。
这里要注意的是,除了能看到的见的字符,比如#include,其实还有看不见的字符,比如空格,换行符,都是一个个ASCII字符,空格是32,换行符是10。
hello.c的内容是高级C语言,是文本文件,大家都能看懂,需要翻译成低级机器语言指令,才能被系统执行。
> gcc hello.c -o hello
> file hello hello.c
hello: Mach-O 64-bit executable x86_64
hello.c: c program text, ASCII text
可以看到hello.c是文本,hello是可执行文件(executable)。
从代码的内容和最终目标,可以记忆编译的四个阶段:
疑问:为什么需要有个中间汇编语言,而不是直接编译成机器语言?
大型C程序编译的时候,会有各种各样的依赖(内部或者外部),了解编译的过程,可以在遇到问题的时候,更快速的找到问题根源,其实在Linux中使用源代码编译安装一些库(比如openssl)的时候就很容易遇到这样的问题;
一个可执行文件的运行,其实就会涉及到系统的各个硬件部件:
hello;执行完的结果,显示在显示器屏幕上;系统硬件层面的缓存(L1,L2,L3),我们在日常开发过程基本上接触不到,但其实应用层面的各种缓存概念大家还是经常接触到的,它的核心思想是一致的:把经常访问的数据放到更高速的存储设备(系统)中来提高程序的性能;
应用程序对硬件的使用都必须要通过操作系统(Linux Kernel),系统调用、内核态、内核模块、驱动程序、用户态这些概念都是跟硬件的使用有关联的。
进程的上下文切换是平时日常中比较常接触到的名词,一般讲到网络编程中,设计高并发处理的时候,进程或线程过多,上下文切换的开销就会拖垮系统的性能,最终导致应用的并发处理能力下降。
虚拟内存空间的各个部分,其实最常接触的就是栈和堆。
这个可以通过打印变量的地址查看。实际开发中,遇到内存越界类的bug,常见现象是程序莫名其妙就crash了,原因就是不小心越界写了其它内存地址,导致看到dump里面crash的位置跟实际出问题的地方完全没有关系,这时候可以通过查看dump中上下内存中的内容来推断是哪里越界了写过来的数据。
并发和并行,实际工作中,接触到应用层的并发概念会更多一些,每秒并发用户数(concurrent user per second),虽然跟系统层面的并发完全不同,但概念相近,一个是同时处理多个用户,一个是同时处理多个任务(process或thread)。并行计算的概念,实际工作中,更多是跟分布式任务结合起来,类似pipeline,比如把一个顺序执行序列的任务,拆分成多个不依赖的子任务并行执行,最后合并结果。
字长(word size)是指针数据的大小,经常讲的32位系统和64位系统,其实就是字长是32位和64位,指针的大小也决定了能够表示的内存空间大小,地址能表示的空间就那么大,所以32位的CPU和操作系统最多只能支持2^32也就是4GB的内存。
字节存储的顺序,大端和小端,下面的程序打印出来的从低到高的字节值,可以看出来就是小端了,大端机器/系统相对少见,我们平常使用的PC机基本都是小端。
#include <stdio.h>
int main() {
int a = 0x01020304;
printf("0x%.8x\n", a);
int *pa = &a;
unsigned char *p = (unsigned char *) pa;
printf("0x%.2x ", *p);
printf("0x%.2x ", *(p+1));
printf("0x%.2x ", *(p+2));
printf("0x%.2x", *(p+3));
return 0;
}
Output:
0x01020304
0x04 0x03 0x02 0x01
一、hello world 生命周期
#include <stdio.h>
int main
{
printf("hello world");
return 0;
}
编译: gcc -o hello hello.c 会车后,通过编译系统,就会生成一个可执行程序hello
编译过程:
1.预处理(cpp)
个人理解:编译器会找到“#include”开头的代码,并将文件内容导入到一个新的文件中,并生成新文件(hello.i)
2.编译(ccl)
个人理解:编译器通过对hello.i的词法分析,语法分析,代码生成,优化等,最终生成hello.s文件
3.汇编(as)
个人理解:汇编器根据指令集,将hello.s文件翻译成机器指令,并打包,生成二进制hello.o文件。
4.链接(ld)
个人理解:hello.o虽然是二进制文件,但还不能执行,因为要需要链接。printf函数是标准c函数,链接器把hello.o和printf.o进行合并。最终得到可执行文件hello。然后加载到内存中执行。
二、个人总结:为什么要理解这个复杂的过程
1.理解敲回车后,程序到底做了什么,比如在编译(ccl)阶段居然还优化了性能。
2.还有一些问题,比如while循环比for效率高吗,switch语句是否比if-else效率高。为什么?这些奇葩问题,不搞懂编译过程,很难回答出来
3.有时候会遇到一些奇葩的错误。比如静态变量和全局变量。有一些链接错误。
4.安全漏洞,比如内存泄漏,缓冲区溢出,要编写出安全的程序,有必要深入学习以上知识。
三、对大端小端的理解
0x1122
既然小端违反人类常识,首先,为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
参考:Errata Security: How to teach endian
四、cpu的高速缓存
未学习之前,一点不知道cpu中还有缓存的概念。
其中一些个人体会:
1.为什么会有cpu的高速缓存?
答:因为cpu运行速度特别快,一般都是ns级别,而内存的访问速度是ms级别,更别说硬盘啦,反正理解就是cpu很强,欲求不满,那么cpu就想了一个办法。
2.大概方案?
答:我每次从内存或硬盘,取到的数据留下一点,放到我的高速缓存中(动态扩容的规则),以备我下次访问。
3.多核之间呢?
答:L1,L2缓存属于各自独立cpu,L3级缓存可以多核之间共享。L1速度>L2速度>L3速度。
4.举个实用例子?
答:个人理解,在nginx配置中,可以通过worker_cpu_affinity指定对cpu和进程之间绑定关系。最大好处就是可以充分利用到cpu的高速缓存。不然进程之间来回切换,出了切换的开销避免不了,缓存也作废了。
五、其他
对于一些内存,磁盘,寄存器,cpu,总线等相关知识书中还未深入开始,在此备注。
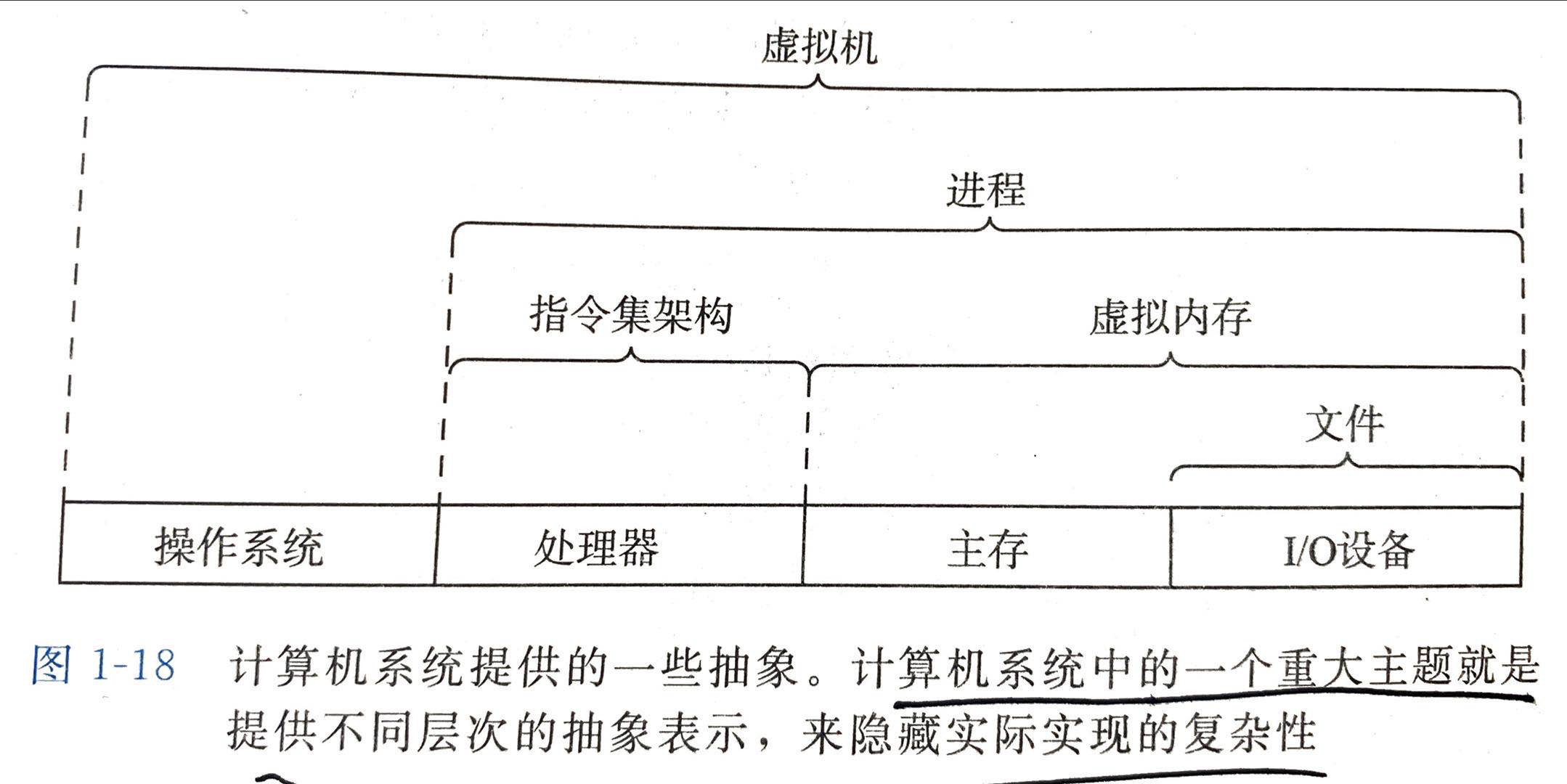
计算机系统抽象的重要性
抽象的目的是通过隐藏实现的复杂性,来应对变化,对外提供统一的一致性。文件、虚拟内存、进程、虚拟机是抽象概念的高层次,API接口、网络ISO模型、类的封装与接口等是更细节的抽象,其中的共性应该都是隐藏实现,维持外部视角的稳定或一致性。从这个角度,我们的生活中各个方面都体现了抽象。比如机动车,不论内部结构怎么变化或改造,基本的驾驶操作是不会变化的。这里汽车对外提供的驾驶操作接口也可以理解为抽象吧。
信息的表示与处理
第二章节的内容很多,足有超过80页,占全书的10%多。最开始读的时候,有点不理解,不就是讲二进制及其运算,搞得这么复杂呀。读到后面的内容,尤其是原理和证明,发现自己的肤浅认识。信息的表示是计算机的实现根基,由于计算机实现是受限的,整数及运算和我们常识中的表示和运算是有差异的,而这一点点的差异会带来软件程序的崩溃,甚至系统的灾难。
整数的转换
整数的转换有两种方式:一种是在位模式不变的前提下进行转换,比如从有符号数强转为无符号数,虽然(物理的)位模式不变,但是转换解析后的数值确发生变化。另一种是通过扩展字长,在数值不变的前提下,比如从short扩展为int。虽然扩展后的(物理的)位模式变化了,但是转换后的数字并不改变。由于转换的差异,这里很容易产生各种意想不到的问题。
1.1 信息就是位+上下文
信息的存储是按位(0和1)存储,8位组成一个字节。从存储介质上,有磁盘文件、内存、网络传输等。区分数据的对象的唯一方法就是读取数据的上下文,不同的上下文对同一个字节序列可能表示不同的信息
1.2 程序被其他程序翻译成不同的格式
翻译流程:Hello.c->预处理器->hello.i->编译器->hello.s->汇编器->hello.o->链接器->hello(可执行程序)
预处理器: include 替换为文件内容
编译器: 输出汇编语言
汇编器: 输出机器指令,输出可重定位目标程序
链接器: 理解不深
1.3 了解编译系统如何工作的有好处
有助于优化程序性能、理解链接时错误、避免安全漏洞
1.7 操作系统管理硬件
操作系统管理硬件,而不是程序直接和硬件打交道,两点考虑:统一的接口、防止滥用硬件
进程感觉自己独占计算机,并发执行由操作系统解决,屏蔽应用程序的复杂性
虚拟内存也是给进程提供一种假象,仿佛自己独占内存,降低应用程序编程复杂性
1.8 系统利用网络通信
1.9 重要主题
Amdahl 定律: 当我们对系统的某个部件加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度
并发和并行: 并发,时间跨度上有重合,同一时间只有一个运行,并行:真正的并行
抽象的重要性:
抽象保证接口的稳定,这样内部逻辑的修改,不会影响依赖方的修改。
我们想象下,如果操作硬件、资源没有统一接口,操作系统一升级,我们所有的应用程序都不能用了,这是灾难啊
操作系统的重要性
计算机系统由硬件和软件组成。操作系统是介于普通软件和硬件之间的一个特殊的软件,所有其他软件对硬件的操作都必须通过操作系统。操作系统通过几个基本的抽象概念(进程、虚拟内存、文件)来管理硬件和服务其他软件。有了操作系统这一层,其他的软件就不用面对硬件的复杂性了,大大降低了软件开发门槛,提高了生产效率。
信息的表示与处理
信息都用比特位表示,一个字节 8 个比特。
字节是最小的寻址单位,意味着不可以访问内存中单独的位。给内存中的所有字节都给定一个唯一的数字标识,然后用 标识 直接访问对应的地址。所有可能地址的集合就称为 虚拟地址空间
表示字符串
因为计算机只存储0和1,表示字符串就需要字符码将数字和字符映射起来。如 ASCII 字符码。
整数的编码
无符号数的编码
向量 x 中的每一个元素表示一个二进制位,其中每一位取值为0或1。即我们理解的二进制转十进制的方法。
$$
B2U_w(x) = \sum^{w-1}{i=0} x_i2_i = x{w-1} \cdot 2^{w-1} + x_{w-2} \cdot 2^{w-2} + …+ x_0 \cdot 2^0
$$
有符号数的编码
有符号数的最高有效位即为符号位,它的权重为 $-2^{w-1}$, 1时为负,0时为非负。由于 0 是非负数,这就导致能表示的整数比负数少一个。
$$
B2U_w(x) = - x_{w-1}2^{w-1} + \sum^{w-1}{i=0} x_i2_i = - x{w-1}2^{w-1} + x_{w-2} \cdot 2^{w-2} + x_{w-2} \cdot 2^{w-2} + …+ x_0 \cdot 2^0
$$
如:
$B2T_4([1111]) = -1 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 = -8 + 4 + 2+ 1 = -1$
值得注意的是 -1 都是补码表示都是一个全1的串,然而这无符号数的最大值的表示一致。
Files such as hello.c that consist exclusively of ASCII characters are known as text files. All other files are known as binary files.
这里的表述不够严谨——仅包含ASCII码的文件固然是文本文件,但是仅包含unicode等编码的文件同样是文本文件。个人觉得wikipedia对text file的解释更到位:“a kind of computer file that is structured as a sequence of lines of electronic text”。对于经常跟编码打交道的程序员来说,我觉得讲清楚更好。
DMA技术可以让disk中的内容直接传输到memory中。
Amdahl法则。很久以前看到过这一章但是对这个法则没有一点点印象;从数学公式上确实平白无奇,不过这次读这节是感觉这条法则对性能分析时还蛮重要的。
作者对并发(Concurrency)和并行(Parallelism)的解说简明扼要:并发指系统中的多个、同一时间段进行的行为,并行指利用并发使系统更快执行。提到了三类并发:Thread-Level Concurrency,Instruction-Level Parallelism,SIMD。其中Thread-Level这块对hyperthreading多了一分理解:就是CPU的一个核心执行一个线程的时候,通常会有部分处理单元闲置;超线程就是同时运行更多的线程,来把闲置的处理单元利用上。这比传统的uniprocessor上整体CPU进行上下文切换的开销要小很多。具体细节还不太明白,需要进一步理解。hyperthreading在操作系统层上往往是不可见的;一般来说,Linux上可以通过echo 0 > /sys/devices/system/cpu/cpu7/online 的方式禁用后N/2个逻辑CPU从而禁用hyperthreading。
作者着重提出了抽象对于计算机系统的重要性。比如对文件是对读写字节设备的抽象;编程语言提供了对二进制指令,而后者是对处理器硬件的抽象。不由得让人想到
“Any problem in computer science can be solved by anther layer of indirection”
计算机系统很复杂,经过一层又一层的抽象才能使得人类和机器更好的交互,不容易。当然,如何抽象、抽象带来的性能问题,又是另一回事了。
本章是综述,很多实际内容作者都提到了要参考后面的章节。作者只列了一些基本概念,我觉得是可以自洽的。内容可以很朴实:讲解了一段hello.c到执行的核心流程,很符合程序员口味。作者是抱着让读者看懂的想法来写的,这点上比好些计算机教材要好很多。。。
程序计数器永远指向主存中下一条指令的位置,其和一系列大小为一个字的寄存器文件,算术/逻辑单元ALU共同完成CPU工作
进程上下文切换是在内核态下发生的,应用程序通过系统调用指令把控制权交给内核(内核是操作系统代码常驻主存的部分)
进程,虚拟内存,文件都是操作系统的抽象模型,让进程以为自己是独立地在使用cpu,主存和I/O设备
每个计算机都有一个字长,其决定了寄存器文件的单元大小和虚拟地址空间的大小,如64位机器,那么一个寄存器单元就是八个字节,其虚拟地址有2^64个字节
虚拟内存中通常字节序列由十六进制字节串来表示,一个字节两位十六进制数,每个8个16进制数组成的地址(32位)储存两个16进制数
异或是相同为0,分清位级运算和逻辑运算,他们是完全不同的,逻辑运算只返回0或1
涉及负数的移位运算,有符号数使用算术右移,无符号数使用逻辑右移
计算机系统中的一个重大主题就是提供不同层次的抽象,来隐藏实际实现的复杂性
1.所在小组:第七组
2.组内昵称:吴奇驴
3.心得体会
所在小组:第三组
组内昵称:hy
心得体会
如今,计算机系统的基本抽象非常类似的,遵循相同的接口规范(POSIX),对这些底层抽象的理解,有助于提升自己的内力,知其所以然;
hello.c 源文件本质就是值 0 和 1 的 bit 组成的序列,8 个 bit 组织成一个 byte(字节),表示文本中的一个字符。8 个 bit 可以对应 2^8 个不同的字符,在 ASCII(美国标准信息交换代码 American Standard Code for Information Interchange) 编码下,取其中 128 个表示 128 个字符,包括大小写字母、数字、标点符号、非打印字符(换行符、制表符等)、控制字符(退格、响铃等);
每个信息都是一个比特串,其代表的意思完全在于上下文中如何解释,例如这 n 个 bit 是整数、浮点数、字符串或者机器指令,都是使用不同的规则(rule)解释出来的,数字有数字的规则,字符串有不同的编码规则;
程序到机器码的过程经过多层次的处理,预处理、编译、汇编、链接,像一个流水线一样,对代码进行处理,每层只做好一件事,得到最终的可执行程序;
系统的硬件提供了软件的载体,在操作系统中,软件可以说是硬件的抽象,总线、I/O设备、内存、处理器,通过对几个核心硬件的了解,我们可以更深入地了解操作系统如何运转,如何变得更快,性能更高。
缓存的重要性毋庸置疑,提到性能优化必提到缓存,在开发中我们尽量使用上层的缓存,利用好局部性原理,把高级缓存的性能利用到极致,像数据库的索引结构 B+ Tree,也是对磁盘和缓存的高效利用,在存储的层次上利用到极致;
进程、虚拟内存、文件这三大抽象,以前只是会使用,通过这次的机会,希望能深入研究下这些抽象实现的原理。抽象是计算机科学最重要的一个概念,各种大佬都在不停地强调这个词:抽象;
Amdahl 定律说白了就是木桶原理嘛,整个系统的提升受限制于最短的木板;
并发、并行、锁机制是高性能系统的热点问题,这里从底层的控制流上阐述并发机制,还是有些启发的;
位运算、逻辑运算、移位运算都是以前理解的知识,没啥重点,网络传输统一都是大端表示法,其实不用记,知道这个概念,写程序的时候如果发现顺序反了,改一下就OK。
下面再介绍下 UTF-8 这个目前使用最广泛的编码:
ASCII 是针对英语设计的,一个 byte 表示一个字符是够的,但是汉语有几万个字符,使用一个 byte 是远远不够的,咋办?多用 1 个字节嘛,为此发明了 UNICODE 使用 2 个字节来表示字符,兼容 ASCII,当属于 ASCII 字符时,前一个字节全为 0。
但是,有了新的问题,对可以使用 ASCII 表示的字符使用 UNICODE 表示并不高效,每个字符都浪费了一个字节,存储空间大了一倍,假设你的源码里只有一个汉字,为了显示这个汉字,所有的英文字母都要使用 2 个字节存储,文件大小翻倍了。
为了解决这个问题,发明了一些中间格式的字符集,称为通用转换格式,即 UTF(Unicode Transformation Format),常见的有 UTF-8、UTF-16、UTF-32。
UTF-8 怎么编码字符呢?
8 表示使用 8 bit 的块表示字符,可以使用 1 - 4 个块表示。
UTF-8 完全兼容 ASCII,使用一个 byte 表示 ASCII,怎么表示呢,其实很简单:
系统读取到的 UTF-8 编码文件是 0 和 1 的字节流,当取出一个字节(8 bit)时:
如果第一位为 0,表示是一个独立的 ASCII 字符;
如果第一位是 1,第二位为 0,表示这个字节为多字节表示字符中的一个组成字节;
如果前两位是 1,第三位为 0,表示当前字节为两个字节表示字符的第一个字节;
如果前三位是 1,第四位为 0,表示当前字节为三个字节表示字符的第一个字节;
如果前四位是 1,第五位为 0,表示当前字节为四个字节表示字符的第一个字节;
因此,根据前两位,是不是 10,可以判断该字节是不是字符编码的第一个字节;如果前两位都是 11 根据前四位,可以确定该字节为字符编码的第一个字节,并且可以判断由几个字节表示。
| 1st Byte | 2nd Byte | 3rd Byte | 4th Byte | Number of Free Bits | Maxinum Expressible Unicode Value |
| — | — | — | — | — | — |
| 0xxxxxxx | | | | 7 | 007F hex(127) |
| 110xxxxx | 10xxxxxx | | | (5 + 6) = 11 | 07FF hex(2047) |
| 1110xxxx | 10xxxxxx | 10xxxxxx | | (4 + 6 + 6) = 16 | FFFF hex(65535) |
| 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | (3 + 6 + 6 + 6) = 21 | 10FFFF hex(1114111) |
可以看到,非首歌 byte 都是使用 10 开头的,除了用作判断规则的 bit,其他 bit 都能用来表示字符,加在一起表示全世界的所有字符还绰绰有余。
1.所在小组:静默组
2.组内昵称:维钢、
3.心得体会
操作系统一直以来掌握的不是很好,借着这次机会,让自己操作系统的知识更加完善和体系化。本周主要看了本书的第一章和第二章,第一章主要概括讲了操作系统各个概念和知识,利用一个hello world小程序让我们对操作系统有了整体的印象。第二章讲的是信息的表示和处理,其中让我们掌握了很多细节,同时这章的学习颇有难度,尤其是大小端字节序,整数有无符号的表示、转换和运算。虽然有些难度,但收获颇丰,继续努力,继续坚持。
笔记:
1.所在小组:一组
2.组内昵称:郝立鹏(组长)
3.心得体会
数学公式的推导和证明我没有看,不是说不重要,而是现在看不懂(数学换给老师了),工作后弄公式证明感觉有点鸡肋。读第一章和第二章时,虽然某些知识点是以前看过的,但是依旧有以下的感悟
一、抽象思想(文件)
Linux抽象出了进程,文件和虚拟内存。我重点说下对文件的理解
文件是对IO设备的抽象,拥有读和写操作的都可能被抽象成文件
比如普通文件是文件,目录文件也是文件,套接字也是文件,字符设备和块设备(如鼠标、键盘、磁盘、外接设备等)也是文件,管道也是文件。
抽象成文件后,对文件的权限操作就是对文件关联的设备的权限操作,简化了操作流程。
对应用层来说,无需关心不同的设备调用什么api来进行读写操作,简化了软件开发流程;
对于内核来说,像英语中“完形填空”一样把具体实现函数注册进操作系统即可,因为所有“文件”都提供的统一的接口(函数)来操作的。
我细想了想,抽像的思想一直伴随着我们的生活和工作。
在工作中,将复杂业务逻辑抽象成不同概念,构建出各种不同模型,将业务逻辑化繁为简,大大降低了开发人员和产品人员的心智负担。这是个很牛逼的能力(我一直也在练习和琢磨,据说做到头是业务架构师)。比如我们公司将流量分析分为抓包、识别、分析、合并、压缩、存储,现在想想,这么设计的人真是人才!
1.所在小组:三组
2.组内昵称:kippa(组长)、wyhqaq、Hongxu、hy、hhhhhhe、MrTrans、晴天、hector、uucloud
3.心得体会
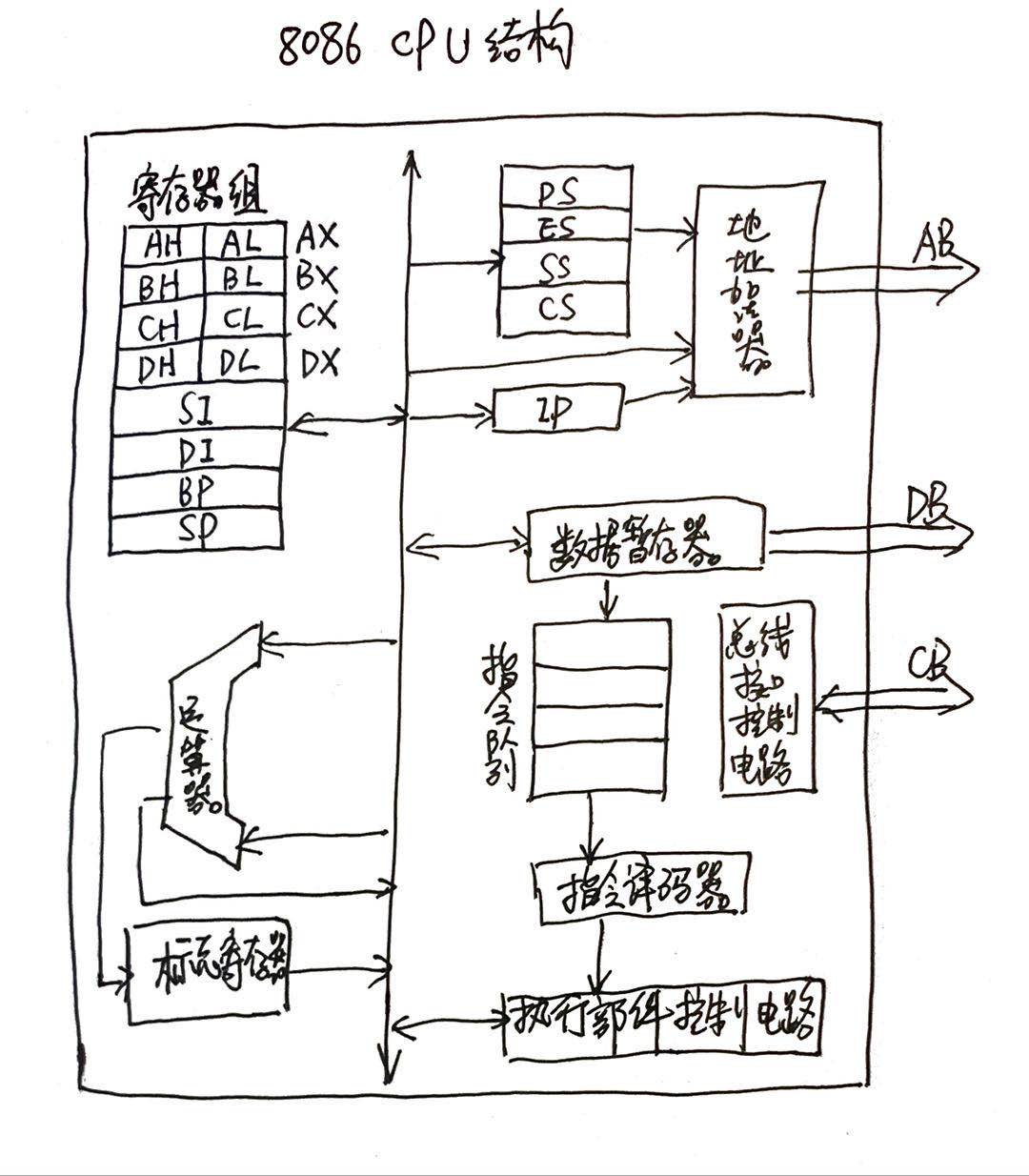
一、CPU 架构
二、存储器层次结构图
| 操作 | 速度 |
|---|---|
| L1 cache reference 读取CPU的一级缓存 | 0.5 ns |
| L1 cache reference 读取CPU的一级缓存 | 0.5 ns |
| Branch mispredict(转移、分支预测) | 5 ns |
| L2 cache reference 读取CPU的二级缓存 | 7 ns |
| Mutex lock/unlock 互斥锁\解锁 | 100 ns |
| Main memory reference 读取内存数据 | 100 ns |
| Compress 1K bytes with Zippy 1k字节压缩 | 10,000 ns/0.01ms |
| Send 2K bytes over 1 Gbps network 在1Gbps的网络上发送2k字节 | 20,000 ns/0.02ms |
| Read 1 MB sequentially from memory 从内存顺序读取1MB | 250,000 ns/0.25ms |
| Round trip within same datacenter 从一个数据中心往返一次,ping一下 | 500,000 ns/0.5ms |
| Disk seek 磁盘搜索/寻道 | 10,000,000 ns /10ms |
| Read 1 MB sequentially from network 从网络上顺序读取1兆的数据 | 10,000,000 ns/10ms |
| Read 1 MB sequentially from disk 从磁盘里面读出1MB | 30,000,000 ns /30ms |
| Send packet CA->Netherlands->CA 一个包的一次远程访问 | 150,000,000 ns/150ms |
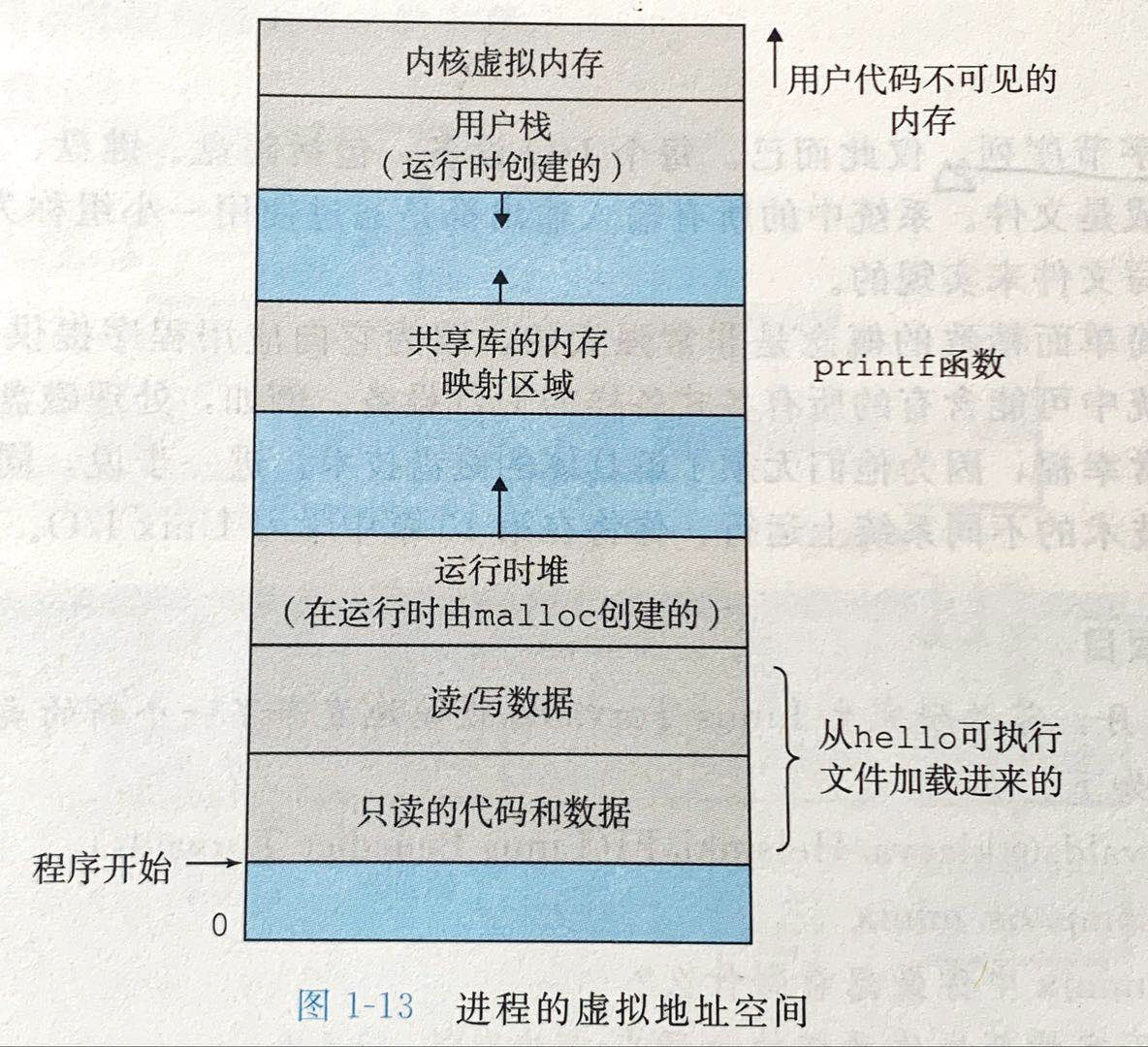
三、虚拟内存
四、计算机系统中的抽象
五、信息存储
Files such as hello.c that consist exclusively of ASCII characters are known as text files. All other files are known as binary files.
这里的表述不够严谨——仅包含ASCII码的文件固然是文本文件,但是仅包含unicode等编码的文件同样是文本文件。个人觉得wikipedia对text file的解释更到位:“a kind of computer file that is structured as a sequence of lines of electronic text”。对于经常跟编码打交道的程序员来说,我觉得讲清楚更好。
DMA技术可以让disk中的内容直接传输到memory中。
Amdahl法则。很久以前看到过这一章但是对这个法则没有一点点印象;从数学公式上确实平白无奇,不过这次读这节是感觉这条法则对性能分析时还蛮重要的。
作者对并发(Concurrency)和并行(Parallelism)的解说简明扼要:并发指系统中的多个、同一时间段进行的行为,并行指利用并发使系统更快执行。提到了三类并发:Thread-Level Concurrency,Instruction-Level Parallelism,SIMD。其中Thread-Level这块对hyperthreading多了一分理解:就是CPU的一个核心执行一个线程的时候,通常会有部分处理单元闲置;超线程就是同时运行更多的线程,来把闲置的处理单元利用上。这比传统的uniprocessor上整体CPU进行上下文切换的开销要小很多。具体细节还不太明白,需要进一步理解。hyperthreading在操作系统层上往往是不可见的;一般来说,Linux上可以通过echo 0 > /sys/devices/system/cpu/cpu7/online 的方式禁用后N/2个逻辑CPU从而禁用hyperthreading。
作者着重提出了抽象对于计算机系统的重要性。比如对文件是对读写字节设备的抽象;编程语言提供了对二进制指令,而后者是对处理器硬件的抽象。不由得让人想到
“Any problem in computer science can be solved by anther layer of indirection”
计算机系统很复杂,经过一层又一层的抽象才能使得人类和机器更好的交互,不容易。当然,如何抽象、抽象带来的性能问题,又是另一回事了。
本章是综述,很多实际内容作者都提到了要参考后面的章节。作者只列了一些基本概念,我觉得是可以自洽的。内容可以很朴实:讲解了一段hello.c到执行的核心流程,很符合程序员口味。作者是抱着让读者看懂的想法来写的,这点上比好些计算机教材要好很多。。。
如今,计算机系统的基本抽象非常类似的,遵循相同的接口规范(POSIX),对这些底层抽象的理解,有助于提升自己的内力,知其所以然;
hello.c 源文件本质就是值 0 和 1 的 bit 组成的序列,8 个 bit 组织成一个 byte(字节),表示文本中的一个字符。8 个 bit 可以对应 2^8 个不同的字符,在 ASCII(美国标准信息交换代码 American Standard Code for Information Interchange) 编码下,取其中 128 个表示 128 个字符,包括大小写字母、数字、标点符号、非打印字符(换行符、制表符等)、控制字符(退格、响铃等);
每个信息都是一个比特串,其代表的意思完全在于上下文中如何解释,例如这 n 个 bit 是整数、浮点数、字符串或者机器指令,都是使用不同的规则(rule)解释出来的,数字有数字的规则,字符串有不同的编码规则;
程序到机器码的过程经过多层次的处理,预处理、编译、汇编、链接,像一个流水线一样,对代码进行处理,每层只做好一件事,得到最终的可执行程序;
系统的硬件提供了软件的载体,在操作系统中,软件可以说是硬件的抽象,总线、I/O设备、内存、处理器,通过对几个核心硬件的了解,我们可以更深入地了解操作系统如何运转,如何变得更快,性能更高。
缓存的重要性毋庸置疑,提到性能优化必提到缓存,在开发中我们尽量使用上层的缓存,利用好局部性原理,把高级缓存的性能利用到极致,像数据库的索引结构 B+ Tree,也是对磁盘和缓存的高效利用,在存储的层次上利用到极致;
进程、虚拟内存、文件这三大抽象,以前只是会使用,通过这次的机会,希望能深入研究下这些抽象实现的原理。抽象是计算机科学最重要的一个概念,各种大佬都在不停地强调这个词:抽象;
Amdahl 定律说白了就是木桶原理嘛,整个系统的提升受限制于最短的木板;
并发、并行、锁机制是高性能系统的热点问题,这里从底层的控制流上阐述并发机制,还是有些启发的;
位运算、逻辑运算、移位运算都是以前理解的知识,没啥重点,网络传输统一都是大端表示法,其实不用记,知道这个概念,写程序的时候如果发现顺序反了,改一下就OK。
下面再介绍下 UTF-8 这个目前使用最广泛的编码:
ASCII 是针对英语设计的,一个 byte 表示一个字符是够的,但是汉语有几万个字符,使用一个 byte 是远远不够的,咋办?多用 1 个字节嘛,为此发明了 UNICODE 使用 2 个字节来表示字符,兼容 ASCII,当属于 ASCII 字符时,前一个字节全为 0。
但是,有了新的问题,对可以使用 ASCII 表示的字符使用 UNICODE 表示并不高效,每个字符都浪费了一个字节,存储空间大了一倍,假设你的源码里只有一个汉字,为了显示这个汉字,所有的英文字母都要使用 2 个字节存储,文件大小翻倍了。
为了解决这个问题,发明了一些中间格式的字符集,称为通用转换格式,即 UTF(Unicode Transformation Format),常见的有 UTF-8、UTF-16、UTF-32。
UTF-8 怎么编码字符呢?
8 表示使用 8 bit 的块表示字符,可以使用 1 - 4 个块表示。
UTF-8 完全兼容 ASCII,使用一个 byte 表示 ASCII,怎么表示呢,其实很简单:
系统读取到的 UTF-8 编码文件是 0 和 1 的字节流,当取出一个字节(8 bit)时:
如果第一位为 0,表示是一个独立的 ASCII 字符;
如果第一位是 1,第二位为 0,表示这个字节为多字节表示字符中的一个组成字节;
如果前两位是 1,第三位为 0,表示当前字节为两个字节表示字符的第一个字节;
如果前三位是 1,第四位为 0,表示当前字节为三个字节表示字符的第一个字节;
如果前四位是 1,第五位为 0,表示当前字节为四个字节表示字符的第一个字节;
因此,根据前两位,是不是 10,可以判断该字节是不是字符编码的第一个字节;如果前两位都是 11 根据前四位,可以确定该字节为字符编码的第一个字节,并且可以判断由几个字节表示。
| 1st Byte | 2nd Byte | 3rd Byte | 4th Byte | Number of Free Bits | Maxinum Expressible Unicode Value |
| 0xxxxxxx | | | | 7 | 007F hex(127) |
| 110xxxxx | 10xxxxxx | | | (5 + 6) = 11 | 07FF hex(2047) |
| 1110xxxx | 10xxxxxx | 10xxxxxx | | (4 + 6 + 6) = 16 | FFFF hex(65535) |
| 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | (3 + 6 + 6 + 6) = 21 | 10FFFF hex(1114111) |
可以看到,非首歌 byte 都是使用 10 开头的,除了用作判断规则的 bit,其他 bit 都能用来表示字符,加在一起表示全世界的所有字符还绰绰有余。
gcc -o hello hello.cPATH,通常Linux下可执行文件会存放在/usr/local/sbin,/usr/local/bin,/usr/sbin,/usr/bin等目录中,shell会查找这些目录下是否有gcc命令。如果有,shell找到该命令文件对应的inode号,获得文件的inode信息,inode信息包括文件在磁盘的数据块位置。找到文件所在的磁盘位置之后,shell开始从磁盘的指定块中读取文件内容(shell会如何读取文件内容?),加载到内存中开始执行(文件如何从磁盘加载到内存?)。#开头的头文件内容和原文件内容一起写入到一个新的以.i结尾的文件中;2、编译阶段:将高级语言指令翻译成汇编,为什么不直接翻译成机器语言?;3、汇编阶段:将汇编翻译成机器指令,将这些指令打包到hello.o文件;4、链接阶段:链接器ld将编译好的hello程序与所用到的库函数链接起来。./hello计算机漫游
信息的表示和处理
大多数计算机都使用8位的块或者字节,作为最小的可寻址内存单位,而不是访问内存中单独的位。
重温16进制,10进制,二进制之间的转换。
同一个数值,整型与浮点型表示二进制,有13个位,序列和位会是相同的。
0,1 也能在布尔的思维下成为代数代数运算。& ^ | ~。
^运算 能够在不引入第三个变量,实现两个数字的交换。
位级运算很基础很重要,位移运算设计逻辑与算术运算。整数的表示,uint64_t-> 9223372036854775807
正如章节标题,漫游计算机系统,第一章从宏观角度讲解了程序从输入到输出的过程中到底发生了什么。有意思的是,作者从程序员的角度,简单明了地说明源程序的编译,以及系统和硬件之间的交互过程。
为什么需要了解编译系统如何工作?
要执行程序 hello 并将其输出到shell,绕不开硬件。系统硬件的组成有:
程序被加载时,指令从磁盘复制到主存;当处理器运行程序时,指令又从主存复制到处理器,而 复制就是开销 。 针对处理器与主存之间的差异,使用高速缓存存储器的局部性(作为暂时的集结区域,存放处理器近期会需要的信息)来提高程序的性能。
理解3个抽象,文件是I/O设备的抽象,虚拟内存是对程序存储器的抽象,而进程是对一个正在进行的程序的抽象。
第 1 章以 hello world 程序为例介绍了计算机硬件组、软件运行过程、存储器层次结构、操作系统管理硬件等内容。
程序运行:预处理 → 编译 → 汇编 → 链接
系统的硬件组成:总线 + I/O设备 + 主存 + 处理器
缓存主要是利用局部性原理来提高程序性能。存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。
操作系统的主要作用是防止防止硬件资源被应用程序滥用以及向应用程序提供简单一致的机制来访问硬件资源。操作系统主要是通过几个抽象(进程、虚拟内存、文件)概念来实现这些功能。
虚拟内存让每个进程都以为自己在独占地使用主存。每个进程看到的是虚拟地址空间,从低到高主要分为程序代码和数据、堆、共享库、栈、内核虚拟内存。
Amdahl 定律:当我们对系统对某个部分进行加速时,其对系统整体虚拟对影响取决于该部分对重要性和加速程度。
并发和并行的三个层次:(1)线程级并发(2)指令级并行(3)单指令、多数据并行
第 2 章主要讲述了如何在计算机上表示信息、处理信息等。
结束