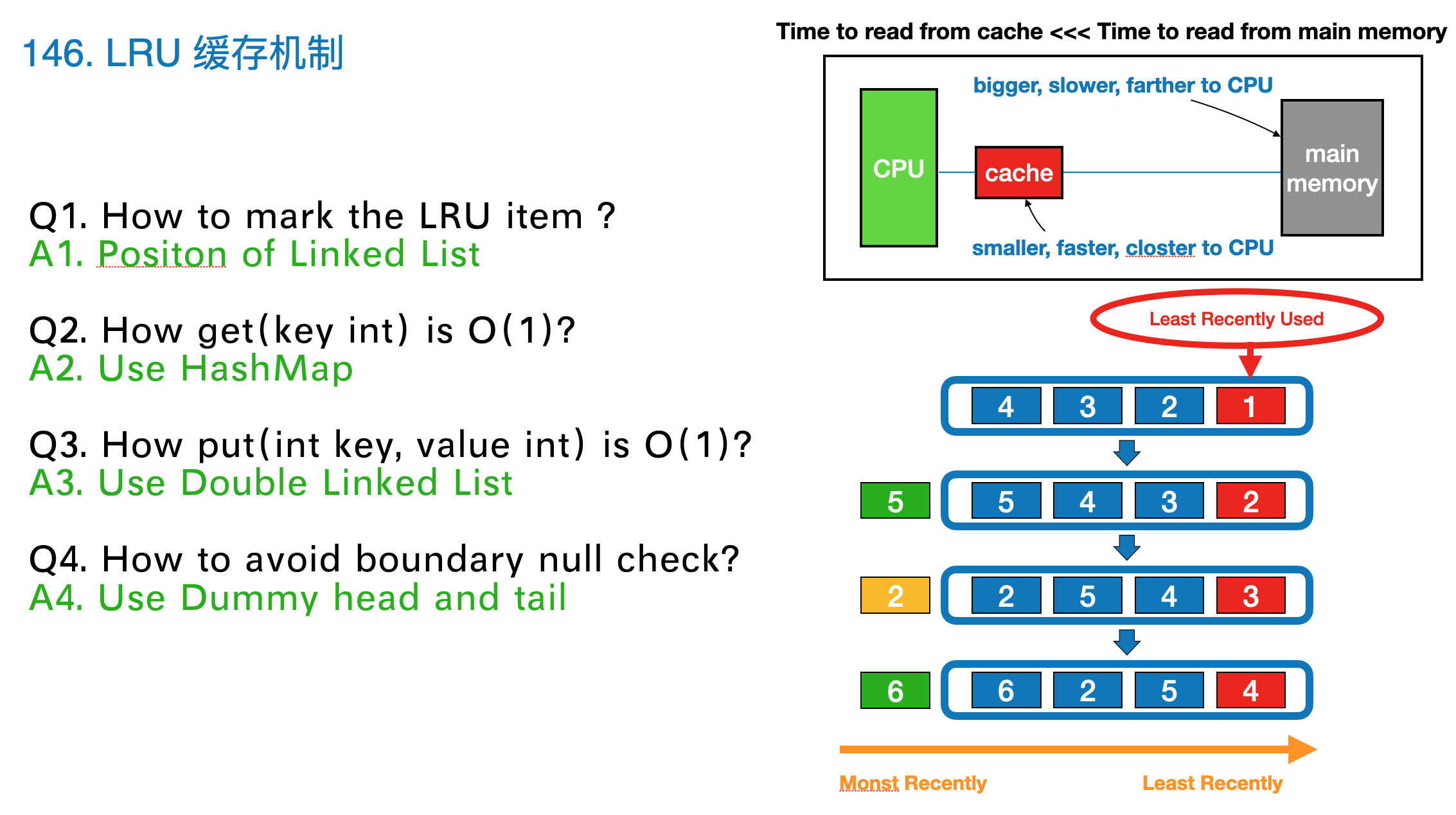
方法一:哈希表 + 双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
-
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
-
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
-
对于 get 操作,首先判断 key 是否存在:
如果 key 不存在,则返回 −1;
如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
-
对于 put 操作,首先判断 key 是否存在:
如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 (1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
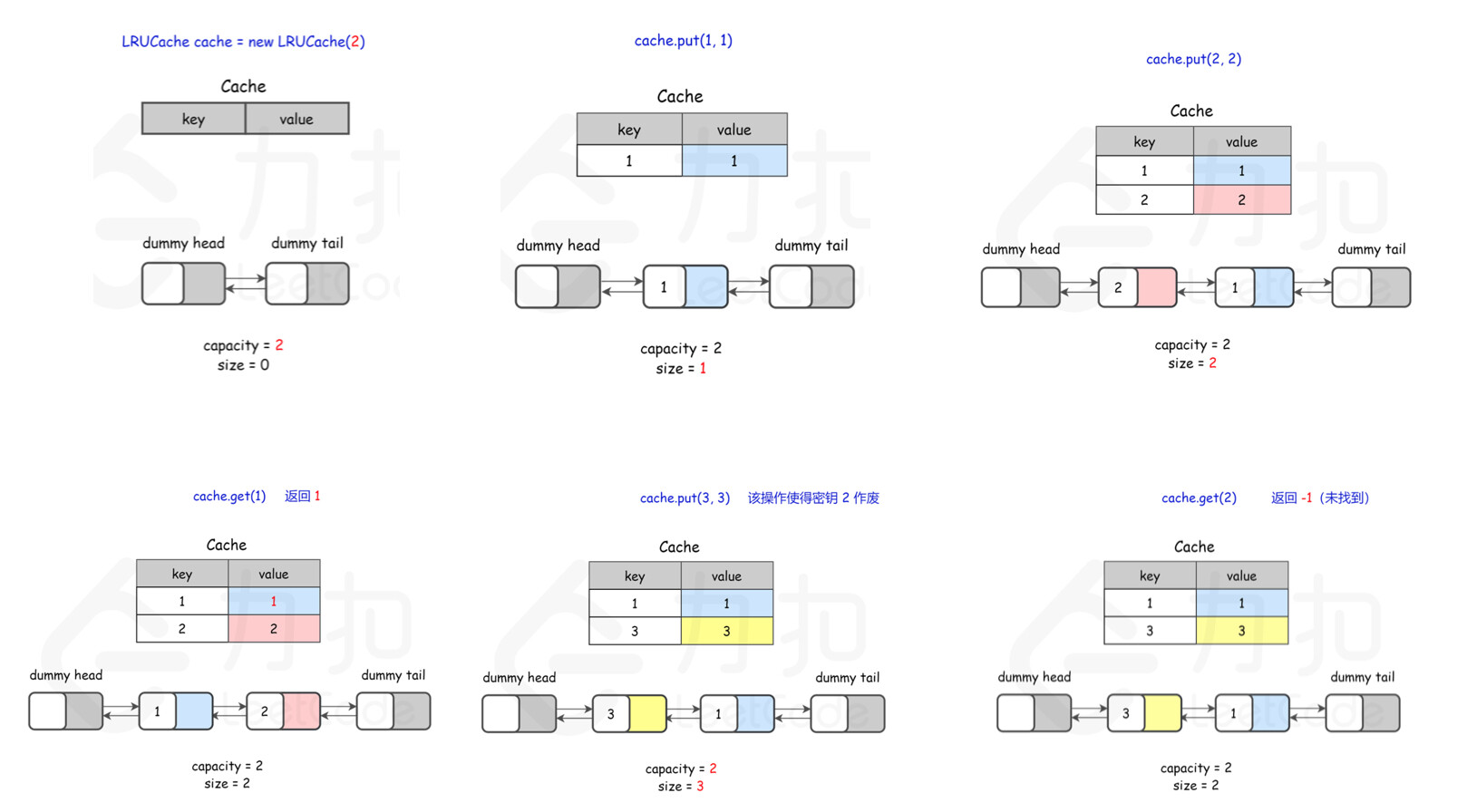
type LRUCache struct {
cache map[int]*DLinkedNode
head, tail *DLinkedNode
size, capacity int
}
type DLinkedNode struct {
key, value int
prev, next *DLinkedNode
}
func initDLinkedNode(key, value int) *DLinkedNode {
return &DLinkedNode{
key: key,
value: value,
}
}
func Constructor(capacity int) LRUCache {
l := LRUCache{
cache: map[int]*DLinkedNode{},
head: initDLinkedNode(0, 0),
tail: initDLinkedNode(0, 0),
capacity: capacity,
}
l.head.next = l.tail
l.tail.prev = l.head
return l
}
func (this *LRUCache) Get(key int) int {
if _, ok := this.cache[key]; !ok {
return -1
}
node := this.cache[key] // 如果 key 存在,先通过哈希表定位,再移到头部
this.moveToHead(node)
return node.value
}
func (this *LRUCache) Put(key int, value int) {
if _, ok := this.cache[key]; !ok { // 如果 key 不存在,创建一个新的节点
node := initDLinkedNode(key, value)
this.cache[key] = node // 添加进哈希表
this.addToHead(node) // 添加至双向链表的头部
this.size++
if this.size > this.capacity {
removed := this.removeTail() // 如果超出容量,删除双向链表的尾部节点
delete(this.cache, removed.key) // 删除哈希表中对应的项
this.size--
}
} else { // 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node := this.cache[key]
node.value = value
this.moveToHead(node)
}
}
func (this *LRUCache) addToHead(node *DLinkedNode) {
node.prev = this.head
node.next = this.head.next
this.head.next.prev = node
this.head.next = node
}
func (this *LRUCache) removeNode(node *DLinkedNode) {
node.prev.next = node.next
node.next.prev = node.prev
}
func (this *LRUCache) moveToHead(node *DLinkedNode) {
this.removeNode(node)
this.addToHead(node)
}
func (this *LRUCache) removeTail() *DLinkedNode {
node := this.tail.prev
this.removeNode(node)
return node
}
复杂度分析
时间复杂度:对于 put 和 get 都是 O(1)。
空间复杂度:O(capacity),因为哈希表和双向链表最多存储 capacity+1 个元素。
type LFUCache struct {
cache map[int]*Node // 存储缓存的内容
freq map[int]*DoubleList // 存储每个频次对应的双向链表
ncap, size, minFreq int // minFreq存储当前最小频次
}
func Constructor(capacity int) LFUCache {
return LFUCache{
cache: make(map[int]*Node),
freq: make(map[int]*DoubleList),
ncap: capacity,
}
}
func (this *LFUCache) Get(key int) int {
if node, ok := this.cache[key]; ok {
this.IncFreq(node)
return node.val
}
return -1
}
func (this *LFUCache) Put(key, value int) {
if this.ncap == 0 {
return
}
if node, ok := this.cache[key]; ok {
node.val = value
this.IncFreq(node)
} else {
if this.size >= this.ncap { // 缓存已满,需要进行删除操作
// 通过 minFreq 拿到 freq_table[minFreq] 链表的末尾节点
node := this.freq[this.minFreq].RemoveLast()
delete(this.cache, node.key)
this.size--
} // 与 get 操作基本一致,除了需要更新缓存的值
x := &Node{key: key, val: value, freq: 1}
this.cache[key] = x
if this.freq[1] == nil {
this.freq[1] = CreateDL()
}
this.freq[1].AddFirst(x)
this.minFreq = 1
this.size++
}
}
func (this *LFUCache) IncFreq(node *Node) {
// 从原freq对应的链表里移除, 并更新 minFreq
_freq := node.freq
this.freq[_freq].Remove(node)
// 如果当前链表为空,我们需要在哈希表中删除,且更新 minFreq
if this.minFreq == _freq && this.freq[_freq].IsEmpty() {
this.minFreq++
delete(this.freq, _freq)
}
node.freq++ // 插入到 freq + 1 对应的链表中
if this.freq[node.freq] == nil {
this.freq[node.freq] = CreateDL()
}
this.freq[node.freq].AddFirst(node)
}
type DoubleList struct {
head, tail *Node
}
type Node struct {
prev, next *Node
key, val, freq int
}
func CreateDL() *DoubleList {
head, tail := &Node{}, &Node{}
head.next, tail.prev = tail, head
return &DoubleList{
head: head,
tail: tail,
}
}
func (this *DoubleList) AddFirst(node *Node) {
node.next = this.head.next
node.prev = this.head
this.head.next.prev = node
this.head.next = node
}
func (this *DoubleList) Remove(node *Node) {
node.prev.next = node.next
node.next.prev = node.prev
node.next = nil
node.prev = nil
}
func (this *DoubleList) RemoveLast() *Node {
if this.IsEmpty() {
return nil
}
last := this.tail.prev
this.Remove(last)
return last
}
func (this *DoubleList) IsEmpty() bool {
return this.head.next == this.tail
}
/**
* Your LFUCache object will be instantiated and called as such:
* obj := Constructor(capacity);
* param_1 := obj.Get(key);
* obj.Put(key,value);
*/
复杂度分析
时间复杂度:get 时间复杂度 O(1),put 时间复杂度 O(1)。由于两个操作从头至尾都只利用了哈希表的插入删除还有链表的插入删除,且它们的时间复杂度均为 O(1),所以保证了两个操作的时间复杂度均为 O(1)。
空间复杂度:O(capacity),其中 capacity 为 LFU 的缓存容量。哈希表中不会存放超过缓存容量的键值对。
LFU实现详解
缓存的大小都是有限的,当缓存满时有新元素需要添加,就需要一种方式从缓存中删除一些元素,删除的策略就是缓存的淘汰算法。
LFU有个兄弟LRU,他们两都是常用的缓存淘汰算法。
LRU(Least Recently Used) 最近最少使用算法,它是根据时间维度来选择将要淘汰的元素,即删除掉最长时间没被访问的元素。
LFU(Least Frequently Used) 最近最不常用算法,它是根据频率维度来选择将要淘汰的元素,即删除访问频率最低的元素。如果两个元素的访问频率相同,则淘汰最久没被访问的元素。
也就是说LFU淘汰的时候会选择两个维度,先比较频率,选择访问频率最小的元素;如果频率相同,则按时间维度淘汰掉最久远的那个元素。
LRU的实现是一个哈希表加上一个双链表
而LFU则要复杂多了,需要用两个哈希表再加上N个双链表才能实现
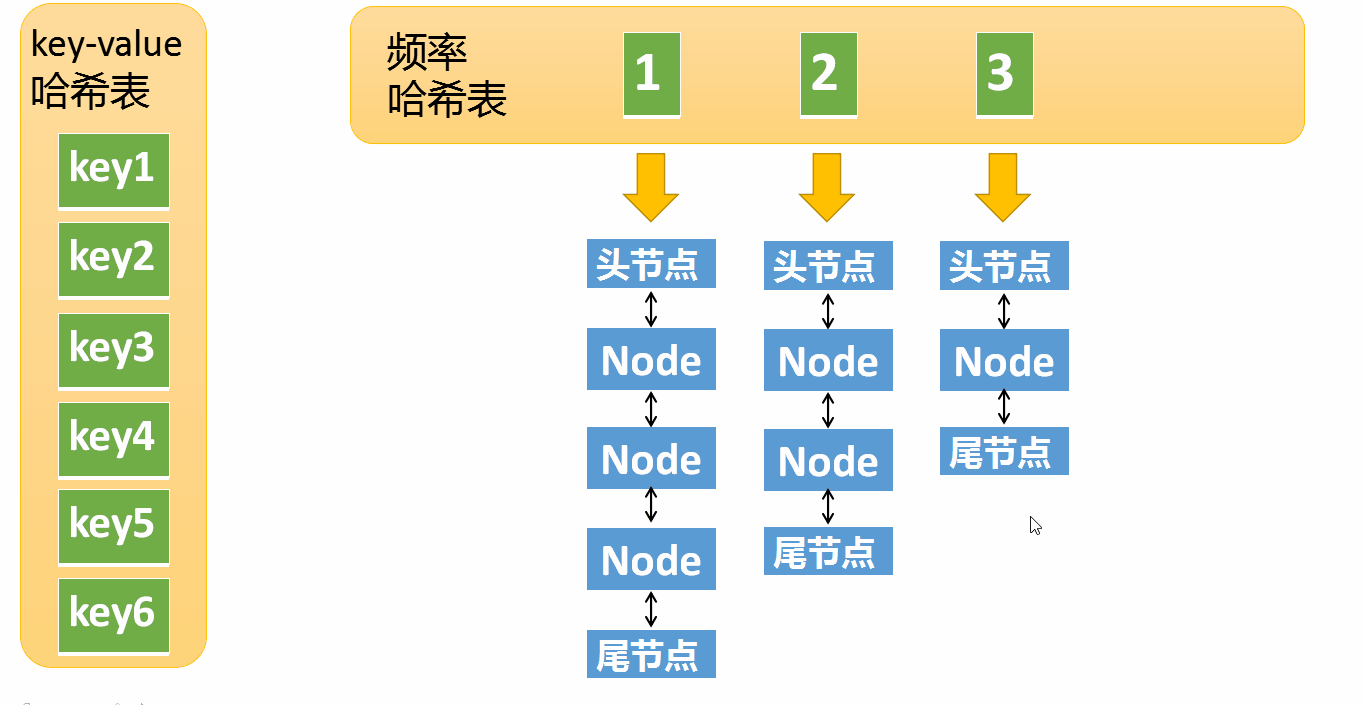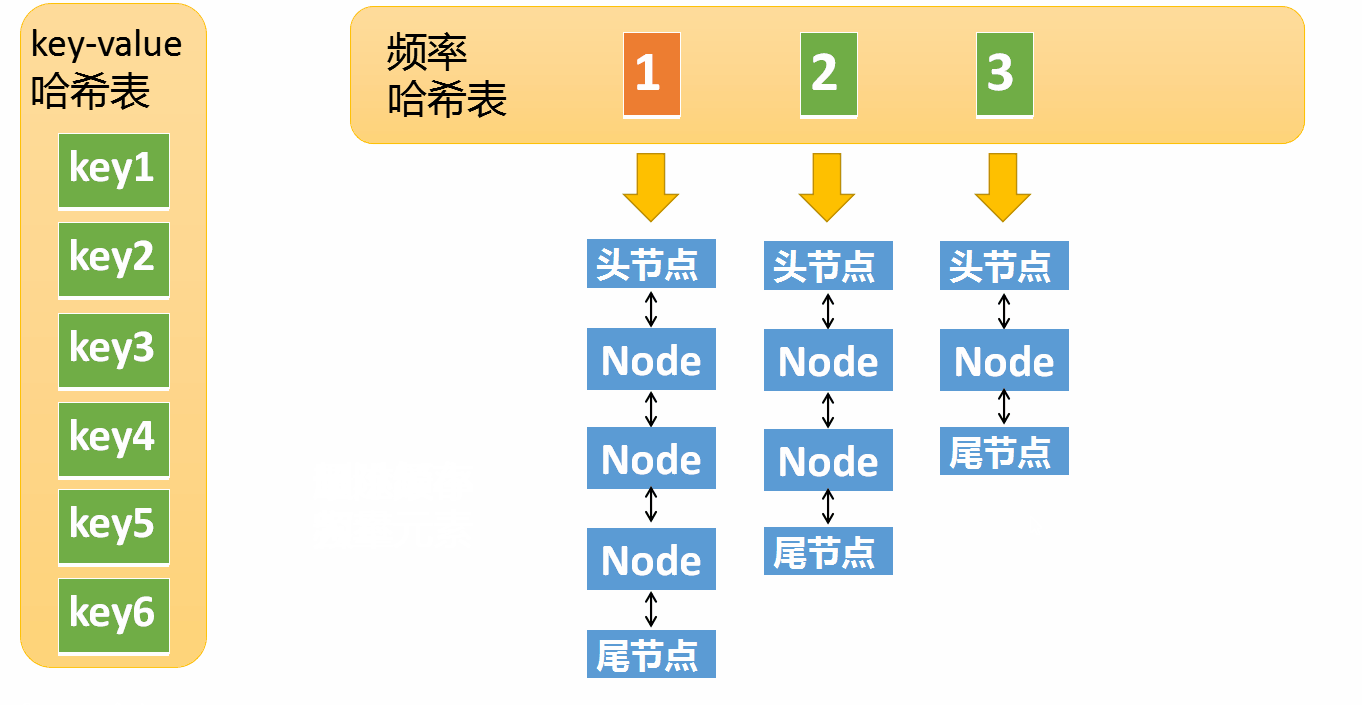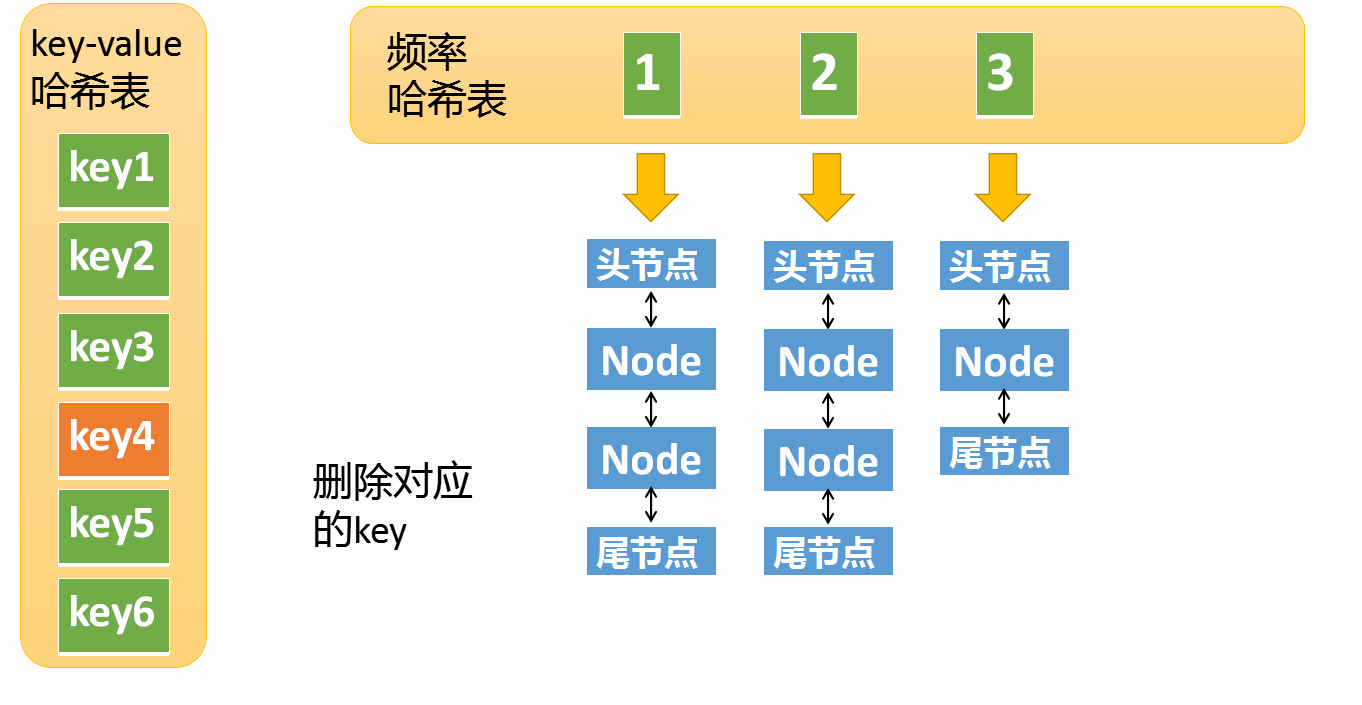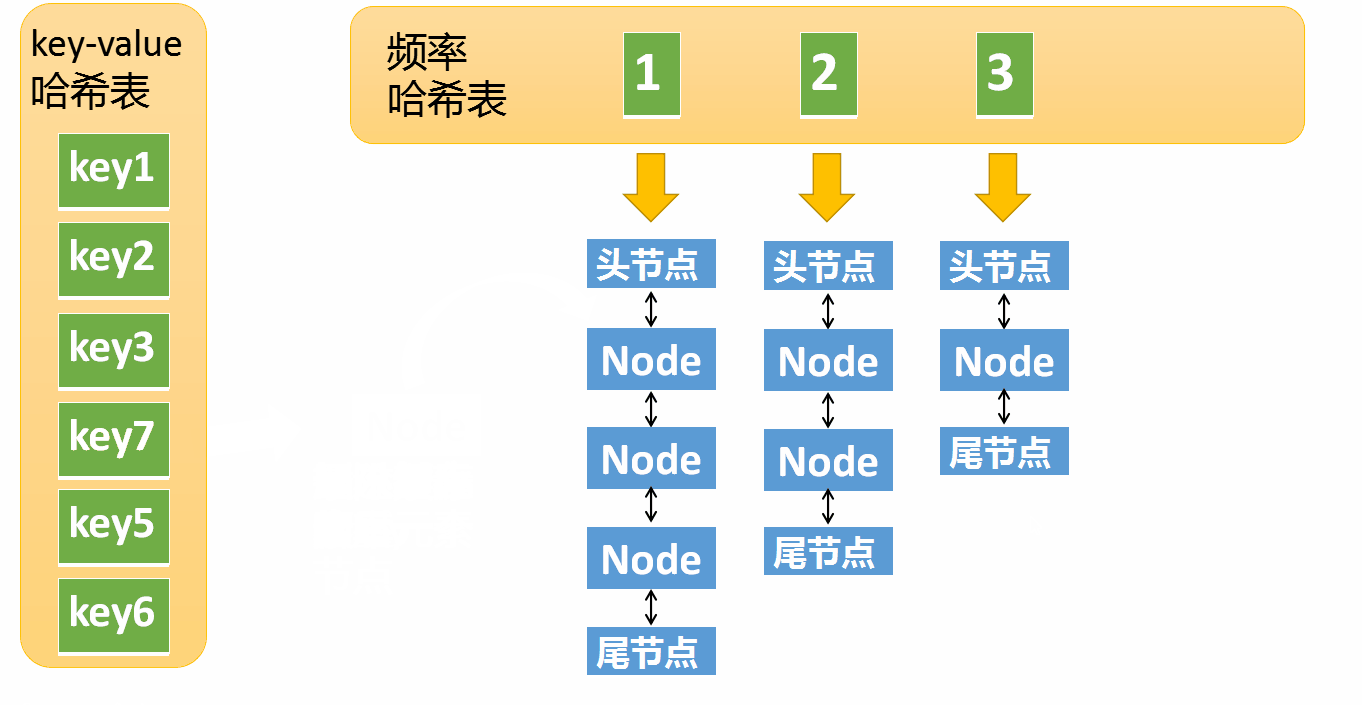
我们先看看LFU的两个哈希表里面都存了什么
第一个哈希表是key-value的哈希表(以下简称kv哈希表)

这里的key就是输入的key,没什么特别的。关键是value,它的value不是一个简单的value,而是一个节点对象。
节点对象Node包含了key,value,以及频率,这个Node又会出现在第二个哈希表的value中。
至于为什么Node中又重复包含了key,因为某些情况下我们不是通过k-v哈希表拿到Node的,而是通过其他方式获得了Node,之后需要用Node中的key去k-v哈希表中做一些操作,所以Node中包含了一些冗余信息。
第二张哈希表,频率哈希表,这个就要复杂多了
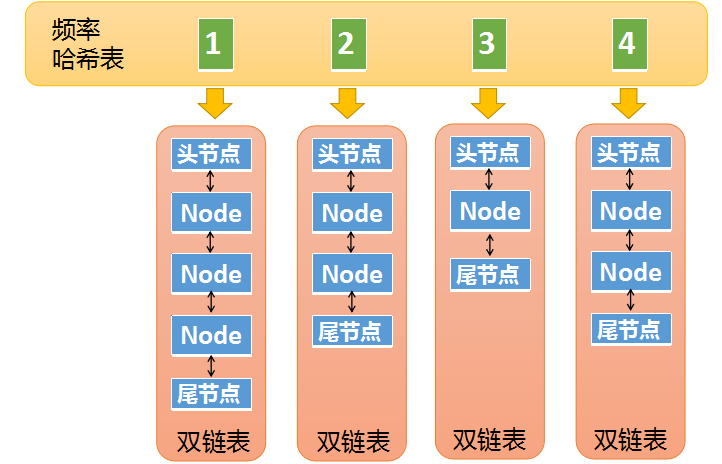
这张哈希表中的key是频率,也就是元素被访问的频率(被访问了1次,被访问了两次等等),它的value是一个双向链表
刚才说的Node对象,现在又出现了,这里的Node其实是双向链表中的一个节点。
第一张图中我们介绍了Node中包含了一个冗余的key,其实它还包含了一个冗余的频率值,因为某些情况下,我们需要通过Node中的频率值,去频率哈希表中做查找,所以也需要一个冗余的频率值。
下面我们将两个哈希表整合起来看看完整的结构:
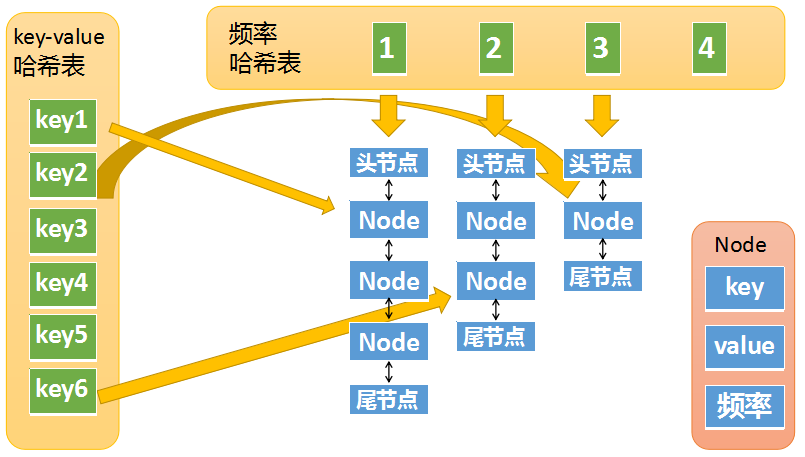
k-v哈希表中key1指向一个Node,这个Node的频率为1,位于频率哈希表中key=1下面的双链表中(处于第一个节点)。
具体操作
下面我们来看看具体操作,get操作相对简单一些,我们就先说get操作吧。
get操作的具体逻辑大致是这样:
如果key不存在则返回-1
如果key存在,则返回对应的value,同时:
将元素的访问频率+1
将元素从访问频率i的链表中移除,放到频率i+1的链表中
如果频率i的链表为空,则从频率哈希表中移除这个链表
第一个很简单就不用说了,我们看下第二点的执行过程
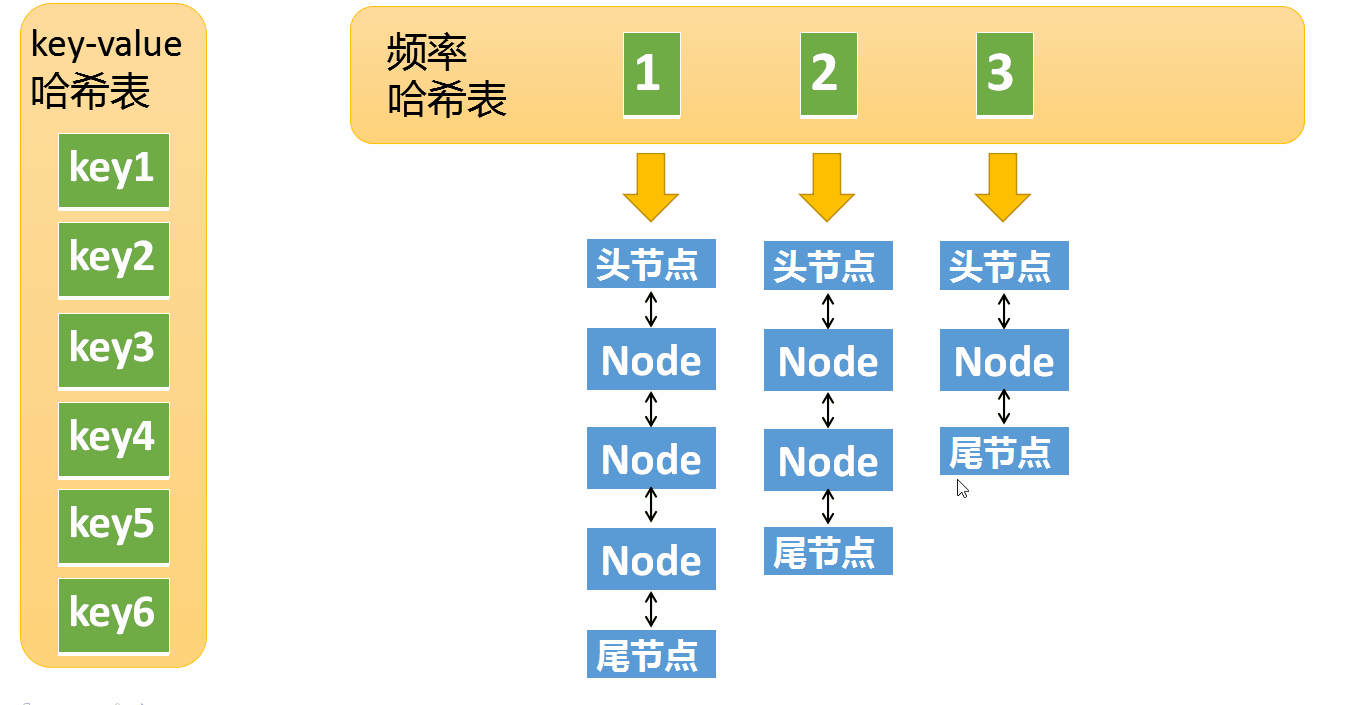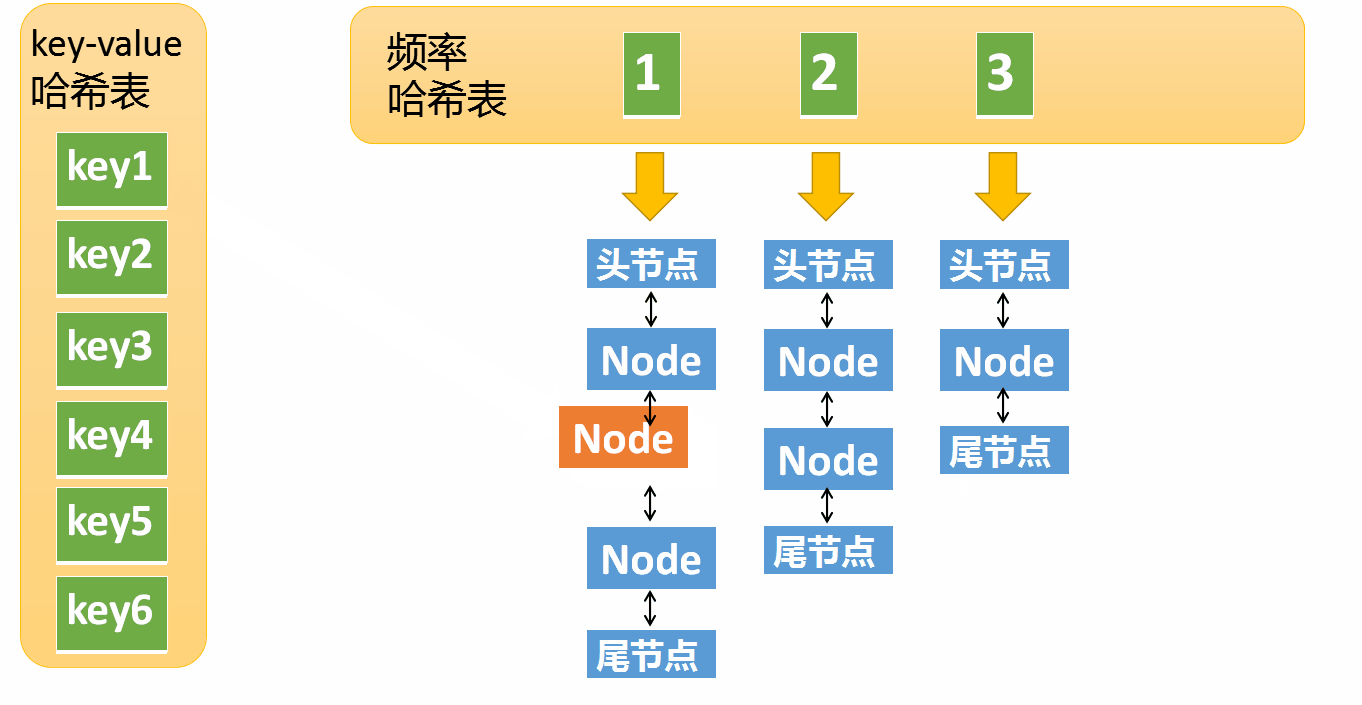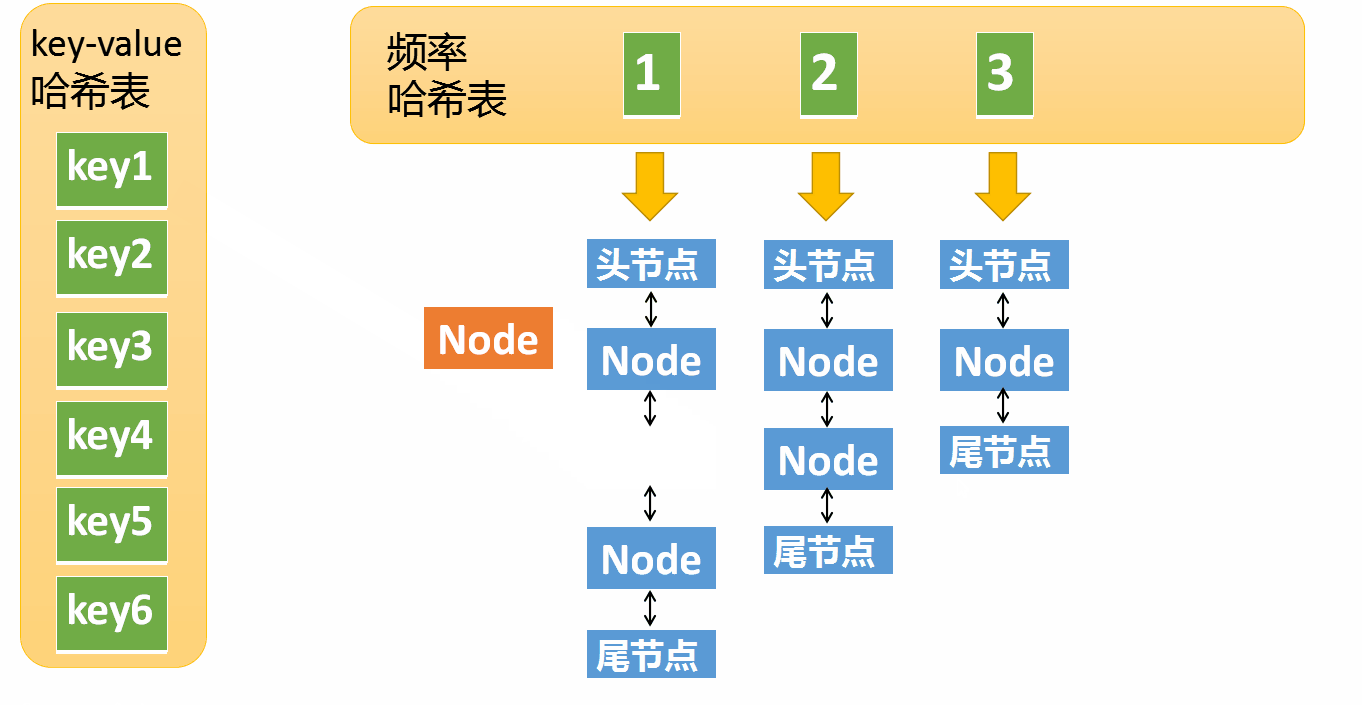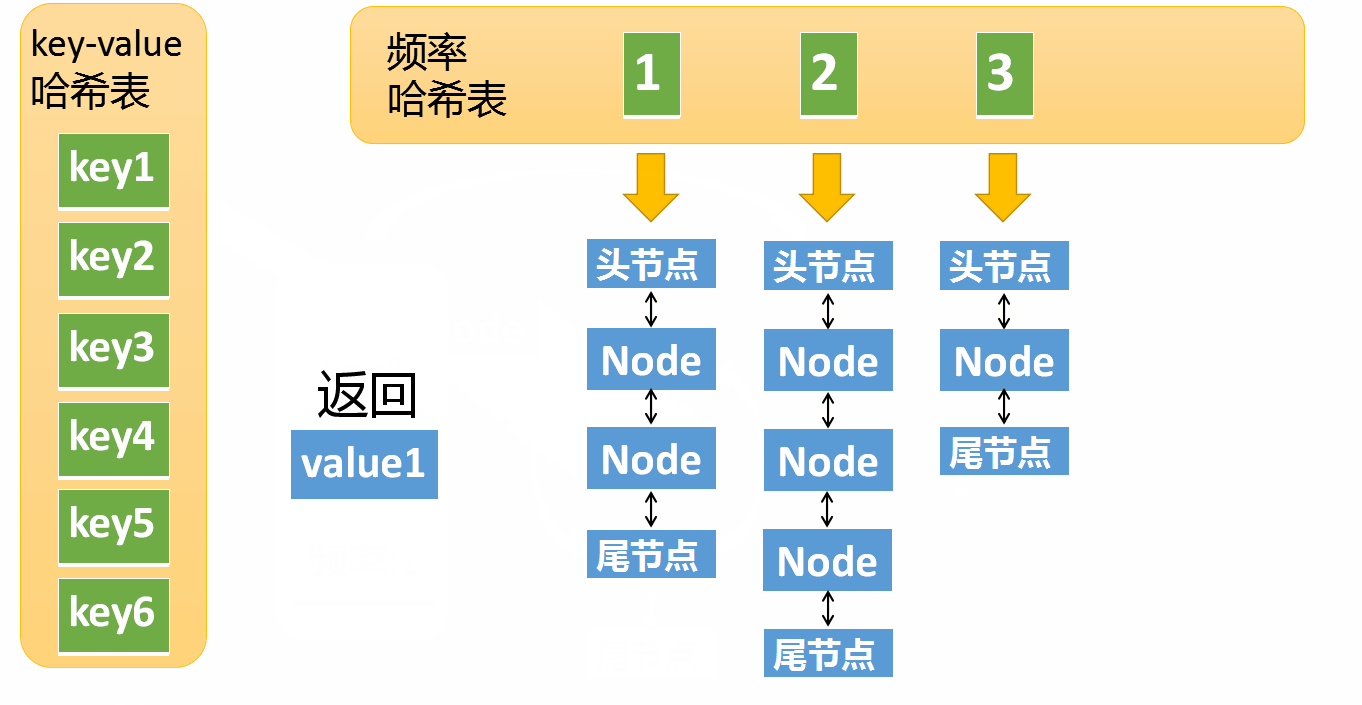
假设某个元素的访问频率是3,现在又被访问了一次,那么就需要将这个元素移动到频率4的链表中。如果这个元素被移除后,频率3的那个链表变成空了(只剩下头结点和尾节点)就需要删除这个链表,同时删除对应的频率(也就是删除key=3)

put操作就要复杂多了,大致包括下面几种情况
如果key已经存在,修改对应的value,并将访问频率+1
将元素从访问频率i的链表中移除,放到频率i+1的链表中
如果频率i的链表为空,则从频率哈希表中移除这个链表
如果key不存在
缓存超过最大容量,则先删除访问频率最低的元素,再插入新元素
新元素的访问频率为1,如果频率哈希表中不存在对应的链表需要创建
缓存没有超过最大容量,则插入新元素
新元素的访问频率为1,如果频率哈希表中不存在对应的链表需要创建
我们在代码实现中还需要维护一个minFreq的变量,用来记录LFU缓存中频率最小的元素,在缓存满的时候,可以快速定位到最小频繁的链表,以达到 O(1) 时间复杂度删除一个元素。
具体做法是:
更新/查找的时候,将元素频率+1,之后如果minFreq不在频率哈希表中了,说明频率哈希表中已经没有元素了,那么minFreq需要+1,否则minFreq不变。
插入的时候,这个简单,因为新元素的频率都是1,所以只需要将minFreq改为1即可。
我们重点看下缓存超过最大容量时是怎么处理的