通过上一篇文章对 dq 生产者的分析,我们知道 dq 是基于 beanstalk 的封装。至于 生产者 我们在后续的文章继续分享,本篇文章先来分析一下 go-queue 中的 kq。
kq 基于 kafka 封装,设计之初是为了使 kafka 的使用更人性化。那就来看看 kq 的使用。
上手使用
func main() {
// 1. 初始化
pusher := kq.NewPusher([]string{
"127.0.0.1:19092",
"127.0.0.1:19092",
"127.0.0.1:19092",
}, "kq")
ticker := time.NewTicker(time.Millisecond)
for round := 0; round < 3; round++ {
select {
case <-ticker.C:
count := rand.Intn(100)
m := message{
Key: strconv.FormatInt(time.Now().UnixNano(), 10),
Value: fmt.Sprintf("%d,%d", round, count),
Payload: fmt.Sprintf("%d,%d", round, count),
}
body, err := json.Marshal(m)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(body))
// 2. 写入
if err := pusher.Push(string(body)); err != nil {
log.Fatal(err)
}
}
}
}
将 kafka cluster 配置以及 topic 传入,你就得到一个操作 kafka 的 push operator。
至于写入消息,简单的调用 pusher.Push(msg) 就行。是的,就这么简单!
当然,目前只支持单个
msg写入。可能有人会疑惑,那就继续往下看,为什么只能一条一条写入?
初始化
一起看看 pusher 初始化哪些步骤:
NewPusher(clusterAddrs, topic, opts...)
|- kafka.NewWriter(kfConfig) // 与 kf 之前的连接
|- executor = executors.NewChunkExecutor() // 设置内部写入的executor为字节数定量写入
- 建立与
kafka cluster的连接。此处肯定就要传入kafka config; - 设置内部暂存区的写入函数以及刷新规则。
使用 chunkExecutor 作用不言而喻:将随机写 → 批量写,减少 I/O 消耗;同时保证单次写入不能超过默认的 1M 或者自己设定的最大写入字节数。
其实再往 chunkExecutor 内部看,其实每次触发插入有两个指标:
maxChunkSize:单次最大写入字节数flushInterval:刷新暂存消息插入的间隔时间
在触发写入,只要满足任意一个指标都会执行写入。同时在 executors 都有设置插入间隔时间,以防暂存区写入阻塞而暂存区内消息一直不被刷新清空。
更多关于
executors可以参看以下:https://zeromicro.github.io/go-zero/executors.html
生产者插入
根据上述初始化对 executors 介绍,插入过程中也少不了它的配合:
func (p *Pusher) Push(v string) error {
// 1. 将 msg -> kafka 内部的 Message
msg := kafka.Message{
Key: []byte(strconv.FormatInt(time.Now().UnixNano(), 10)),
Value: []byte(v),
}
// 使用 executor.Add() 插入内部的 container
// 当 executor 初始化失败或者是内部发生错误,也会将 Message 直接插入 kafka
if p.executor != nil {
return p.executor.Add(msg, len(v))
} else {
return p.produer.WriteMessages(context.Background(), msg)
}
}
过程其实很简单。那 executors.Add(msg, len(msg)) 是怎么把 msg 插入到 kafka 呢?
插入的逻辑其实在初始化中就声明了:
pusher.executor = executors.NewChunkExecutor(func(tasks []interface{}) {
chunk := make([]kafka.Message, len(tasks))
// 1
for i := range tasks {
chunk[i] = tasks[i].(kafka.Message)
}
// 2
if err := pusher.produer.WriteMessages(context.Background(), chunk...); err != nil {
logx.Error(err)
}
}, newOptions(opts)...)
- 触发插入时,将暂存区中存储的
[]msg依次拿出,作为最终插入消息集合; - 将上一步的消息集合,作为一个批次插入
kafka的topic中
这样 pusher -> chunkExecutor -> kafka 一个链路就出现了。下面用一张图形象表达一下:
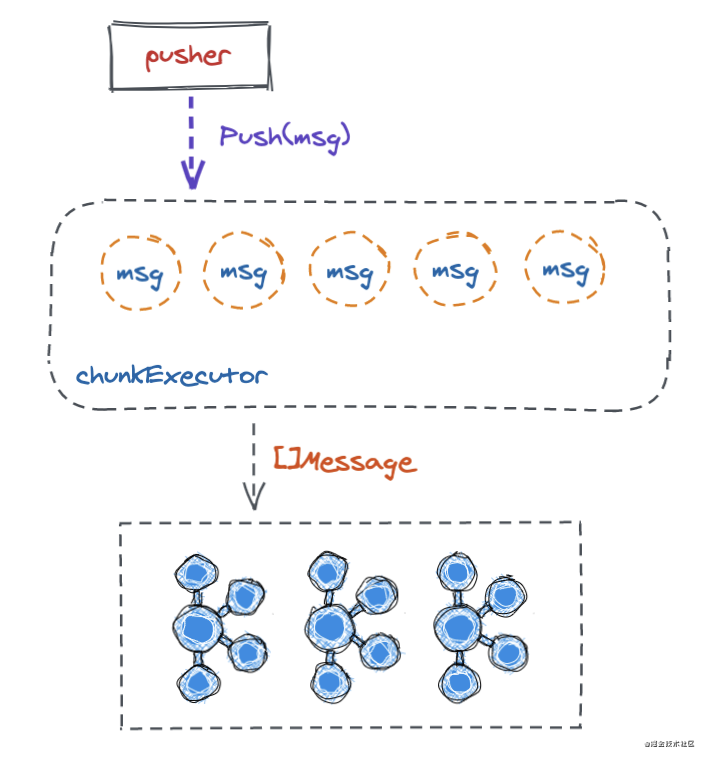
框架地址
https://github.com/tal-tech/go-queue
同时在 go-queue 也大量使用 go-zero 的 批量处理工具库 executors。
https://github.com/tal-tech/go-zero
欢迎使用 go-zero & go-queue 并 star 支持我们!一起构建 go-zero 生态!![]()