请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:
所在小组
第一组
组内昵称
张三
你的心得体会
可以基于不同知识点进行,有更新请在原回贴更新,每人每周只发一个帖子
一段自己的阐述
第二段自己的阐述
…
请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:
第一组
张三
可以基于不同知识点进行,有更新请在原回贴更新,每人每周只发一个帖子
…
第七组
杨文
程序所需数据存储在高速缓存中,在指令的执行期间,在0个周期内就能访问到。在高速缓存中,需要4-75个周期,在主存中,则需要上百个周期。在磁盘中,则需要大约几千万个周期。
(为什么是 4-75个周期呢?)
局部性原理:在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。

所在小组: 静默组
组内昵称: 维钢、
心得体会:
随机访问存储器分为两类:静态RAM(SRAM)和动态RAM(DRAM)。
静态RAM将每个位存储在一个双稳态的存储器单元里,它可以无限期地保持在两个不同的电压配置或状态之一,在其他状态时会快速地转移到两个稳态状态中的一个。
动态RAM将每个位存储为对一个电容的充电,每个单元由一个电容和一个访问晶体管组成。
传统DRAM芯片的单元由一个二维的超单元组成,每个超单元含有8个bit,这样若干个芯片被封装到一个内存模块中,多个内存模块连接到一个内存控制器上,从而聚合成主存。在取内存A处到一个字时,由内存控制器选择包含A的模块,然后将A转换成(i,j)的形式,发送到对应模块,然后内存模块再将i和j广播到每个DRAM芯片,每个芯片会输出它的(i,j)位置的超单元中的8位内容,模块收集所有芯片的内容后合并成字返回给内存控制器。
CPU和DRAM之间用总线连接,总线分为系统总线和内存总线,系统总线连接CPU中的总线接口和我们称之为I/O桥的芯片组(其中包括内存控制器),内存总线连接I/O桥和主存。
局部性 :一个编写良好程序倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。时间局部性指在引用过一次的内存位置很可能在不远的将来再被多次引用,空间局部性是一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
把一个程序会经常访问的一系列空间集合叫做这个程序的工作集,当工作集的大小超过缓存的大小时,缓存会经历容量不命中,程序会发生抖动。
| 名词 | 解释 |
|---|---|
| RAM 随机访问存储器(Random-Access Memory) | |
| SRAM 静态随机访问存储器 | 高速缓存存储器,既可以在CPU芯片上,也可以在片下。采用六晶体管电路来实现, 只要有电,就会永远地保持它的值 |
| DRAM 动态 | 即常见的内存,采用电容来显示,对干扰非常敏感 |
| DDR3 SDRAM(Double Data-Rate Synchronous DRAM) | 双倍速率同步DRAM 使用两个时钟沿作为控制信号,从而使DRAM的速度翻倍 |
| ROM(Read-Only Memory) 只读存储器 | 非易失性存储器 |
| EEPROM(Electrically Erasable Programmable ROM) | 电子可擦写可编程ROM |
| 总线事务(bus transaction) | CPU和主存之间的数据传送,分为读事务和写事务 |
| PCIe(Peripheral Component Interconnect express) | 外围设备互连总线,对接I/O设备 |
| DMA传送(Direct Memory Access transfer) | 直接内存访问 传送 |
| 名词 | 解释 |
|---|---|
| 顺序引用模式(sequential reference pattern) | 步长为1的引用模式(stride-1 reference pattern), 一般而言,随着步长的增加,空间局部性下降 |
| cache | 读作"cash" |
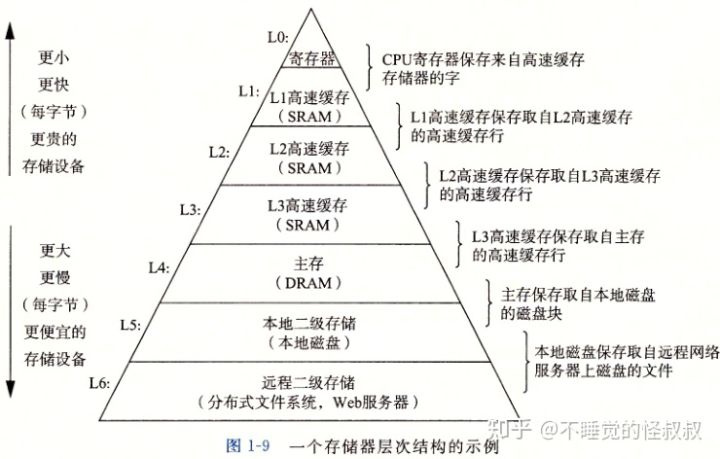
存储器层次结构的中心思想是: 对于每个k, 位于k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。换句话说,层次结构中的每一层都缓存来自较低一层的数据对象
MMU是CPU芯片的一部分,而TLB(快表)是MMU的一部分。TLB(Translation Lookaside Buffer): 被用作地址翻译,专门用于改进虚拟地址到物理地址转换速度的缓存。其访问速度非常快,和寄存器相当,比L1访问还快。
第二组
Joey
存储器的缓存思想依赖程序的局部性(时间局部性和空间局部性),基于局部性的缓存设计体现在单机程序设计/分布式系统设计的方方面面。
主存分为DRAM和SRAM,他们断电都丢数据。但是DRAM漏电需要刷新,掉电也会丢失,便宜。SRAM不需要刷新(双稳态),速度也快(就是贵)
机械硬盘一次寻址需要寻道(几毫秒)、旋转(几毫秒,和寻道大致相等)、传送(微秒),定位到要读取的字节是最慢的,访问时间与其相比几乎可以忽略不计。和主存的访问速度有千倍差距。磁盘的格式化只是在磁道之间的GAP里添加一些标志信息,比如是否已经格式化,是否坏道等。
操作系统对固态硬盘和机械硬盘都提供了相同的抽象
读写速度方面,机械硬盘的随机读写速度按原理来讲是差别不大的(因为感觉大头是寻址和旋转)。但是固态硬盘的写速度比读速度慢很多。
即使程序有良好的空间局部性,但是如果缓存中没有足够的容量,有的检索可能会造成缓存反复失效、反复加载,这叫缓存抖动,这种抖动让速度下降得比没有缓存还差。这在计算机体系中的缓存和分布式系统中的缓存都是一个道理,看来基础真的很重要~
直写(write-through)和写回(write-back)策略也在分布式系统设计有涉及。直写会造成较大的总线流量,而写回实现较为复杂。推荐阅读https://coolshell.cn/articles/17416.html 《缓存更新的套路》
衡量缓存性能的指标:命中率、命中时间、不命中处罚
编写局部性较好的程序:数组索引的步长(最好为1)、对局部变量的重复引用和把注意力集中在内层的循环上
第五组
王传义
缓存无处不在,是存储器的本质。
这里从文件系统和函数讨论与缓存的关系。
一 .如何判断一个函数具备告诉缓存友好型(重复利用缓存局部性)
对数组的顺序遍历step越小好,step=1(why 数据在空间上连续存储。顺序读取4字节出现第一次不命中,后面3次命中 命中概率3/4)
对局部变量反复引用(why 可以局部变量存储寄存器上)
二维数组循环,按照行读取命中大于列读取(课本上例子 前者概率3/4,后者是0)
二. 文件缓存是一个重要缓存(slabtop查看)
虚拟文件系统(对不同文件系统的抽象)
文件系统(参考第一期性能优化 )
目录项(完全是内存缓存,100% ),
索引节点(一个inode长度固定,文件内容会缓存到页缓存 Cache 中),
数据块(文件内容会缓存到页缓存 Cache 中),
超级快(存储整个文件系统的状态)
第三组
hy
存储器存放指令和数据,抽象成一个线性的字节数组,CPU 在常数时间内可以访问每个数组的每个位置。
这里的 Trade Off 是存储器的访问速度和容量成反比,容量越大访问速度越慢,而容量小的寄存器、CPU 缓存访问速度非常快。而且容易越大的存储器越便宜。在这种情况下,我们需要达到经济实惠且性能尽可能高的目标,就需要尽量使用高速存储器,提前把后续需要使用的数据一次性加载到高速缓存中,也就是局部性原理。
编写具有良好局部性的程序会一次又一次访问相同的数据或领近的数据,这样会使程序运行得更快,在架构设计中我们对热点数据引入进程缓存、远程缓存都是这个原理的应用。
RAM(Random Access Memory)
随即访问存储器分为动态(dynamic)DRAM 和静态(static)SRAM 两种,SRAM 比 DRAM 更快也更贵,一分钱一分货。
SRAM 作为高速缓存存储器用在 CPU 芯片上,不会超过几兆字节,L1、L2、L3 缓存就是这个,每个单元使用一个六晶体管电路(贵),不易被干扰,只要有电就会保持不变。
DRAM 作为内存,一般有几千兆字节,例如 16G 内存条,每个单元使用一个电容和一个访问晶体管(便宜)。容易被干扰,需要不断刷新,暴露在光下会导致电容电压改变,数码相机和摄像机中的传感器本质就是 DRAM 单元的阵列。
ROM(Read-Only Memory) 存储器:只读的存储器,一般用在 BIOS 开机上。
磁盘:核心在于寻道时间、旋转时间,数据尽量写在相近的位置,避免寻道,这也是磁盘顺序写性能还不错的原因。
固态硬盘 SSD(Solid State Disk):在替代磁盘提升硬件性能上非常给力,由闪存芯片和闪存翻译层组成,读比写要快。数据以页为单独读写,但只有页所属的块被整个擦除(耗时 1ms)才能写这个页,一个块在 100000 次的擦除和重写后就会损坏,不能继续使用,所以 SSD 的寿命比磁盘更短,但是用个几年不成问题,因此在各种电子设备上大量普及,成本也降下来了。
静默组
Han
存储设备近年来的最能够感知的变化就是ssd硬盘的普及(当然价格更便宜了),在如今海量数据的时代,面向存储编程转向面向数据编程,海量实时数据的读写对底层存储也提出了巨大的要求,ssd硬盘已经在服务器领域非常广泛,数据实时分析和查询都需要更快的从硬盘中读取数据。
局部性原理,其实从应用层来理解更容易:
缓存的使用实在是太广泛了,数据的流转真的是可以理解成在一级级缓存间切换,每一个存储单元既是存储载体也是下一级的缓存载体,硬件层面的缓存可能接触不到,但是应用程序面其实在各种复杂的数据管理系统中广泛存在,最典型的就是关系型数据库系统。
缓存的读的逻辑相对写而言容易一些,多级缓存的写容易产生数据不一致的问题,进而影响读和数据的安全性。
缓存友好的策略,聚焦最常见运行代码块,这与性能优化的核心思想类似,着重优化最常用的流程,可以让性能优化事半功倍,82法则。日常大家编码代码可能无需关注,科学计算领域对这些点会更关注,有时候与其自己造轮子,找到合适的已有的优化好的计算库来完成工作会更有效。
所在小组: 静默组
组内昵称: Tang_D
心得体会:
第五组
chensongbin
Subject: The Memory Hierarchy 储存结构
Author: @陈松彬
Date: 2020-10-25
分为时间局部性和空间局部性
缓存能提高效率的根本原因是因为运行的程序拥有局部性
三种高速缓存组织结构,主要区别是E的不同(E高速缓存组中cache line的数目)
直接映射高速缓存
E = 1
组组相联高速缓存
1 < E < C/B
全相联高速缓存
E = C/B
确定某个cache line需要并行的搜索整个高速缓存组
制造困难 成本高
全相联高速缓存只适合做小的高速缓存。eg:用于虚拟内存系统中的翻译备用缓冲器(TLB),缓存页表项
在以前CPU单核的时候,处理器性能的提升,是依靠缩短现一个CPU的时钟周期
但现在缩短一个CPU的时钟周期已经比较困难,因此现在都是向着多核CPU发展
因此编程也朝着多线程并发编程的方向发展,写出正确的多线程代码,可以大大提高程序的运行效率
举一个多线程利用Cache Line提高性能的例子:
基本原理是:False Sharing https://en.wikipedia.org/wiki/False_sharing
// sum总共使用16字节,在同一个cache line上,一个核心的L1 cache修改,会导致其他核心的cache失效
var sum []int{0, 0, 0, 0}
func main(){
go addOne(0)
go addOne(1)
go addOne(2)
go addOne(3)
time.sleep(100)
}
func addOne(i int){
for i:=0;i<1000;i++{
sum[i]++
}
}
一个简单的优化方式是,增加padding,使得不同线程修改的变量不要分配在同一个cache line上
var sum []int{
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 64字节
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 64字节
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 64字节
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 64字节
}
func main(){
go addOne(0) // cache line 中的第一个int
go addOne(16) // cache line 中的第一个int
go addOne(32) // cache line 中的第一个int
go addOne(48) // cache line 中的第一个int
time.sleep(100)
}
func addOne(i int){
for i:=0;i<1000;i++{
sum[i]++
}
}
第六组
蒋权
存储器系统 是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU寄存器 保存着最常用的数据。靠近CPU的小的、快速的高速缓存(SRAM) 作为一部分存储在相对慢速的主存储器(DRAM) 中数据和指令的缓冲区域。主存储器(DRAM) 缓存存储在容量较大的、慢速磁盘(本地磁盘) 上的数据,而这些磁盘常常又作为存储在通过网络连接的其他机器的磁盘或磁带(分布式文件系统,Web服务器) 上的数据的缓存区域。
局部性 是计算机程序的一个基本属性。具有良好局部性的程序倾向于一次又一次地访问相同的数据项集合,或是倾向于访问邻近的数据项集合。具有良好局部性的程序比局部性差的程序更多地倾向于从存储器层次结构中较高层次处访问数据项,因此运行得更快。
随机访问存储器(RAM)分为两类:静态RAM(SRAM)和动态RAM(DRAM)。
1、静态RAM
SRAM将每个位存储在一个双稳态的存储器单元里,每个单元用六个晶体管电路实现(成本相对高)。双稳态就是电路可以无限期地保持在两个不同的电压配置或状态之一。其他任何状态都是不稳定的——从不稳定状态开始,电路会迅速地转移到两个稳定状态中的一个。
由于双稳态特性,SRAM只要有电,它就会永远保持它的值(抗干扰性强)。
2、动态RAM
DRAM将每个位存储为对一个电容的充电,每个单元由一个电容和一个访问晶体管组成(成本相对低)。与SRAM不同,DRAM存储器单元对干扰非常敏感(抗干扰性弱)。当电容的电压被扰乱之后,它就永远不会恢复了。暴露在光线下会导致电容电压改变。
内存系统必须周期性地通过对DRAM读出,然后重写来刷新内存每一位。
SRAM和DRAM的对比:
3、传统的DRAM
DRAM芯片中的单元(位)被分成d个超单元,每个超单元由 个DRAM单元组成。一个d *
的DRAM总共存储了d
位信息。
超单元被组织成一个r行c列的长方形矩阵,其中r * c = d。
每个超单元有形如(i, j)的地址,i表示行,j表示列。
信息通过称为引脚的外部连接器流入和流出芯片。每个引脚携带一个1位的信号。
有两种引脚:
每个DRAM芯片被连接到某个称为"内存控制器"的电路,内存控制器通过addr引脚和data引脚与DRAM进行数据的交互。
4、内存模块
DRAM芯片封装在内存模块中,它插到主板的扩展槽上。
Core i7系统使用240个引脚的双列直插内存模块。
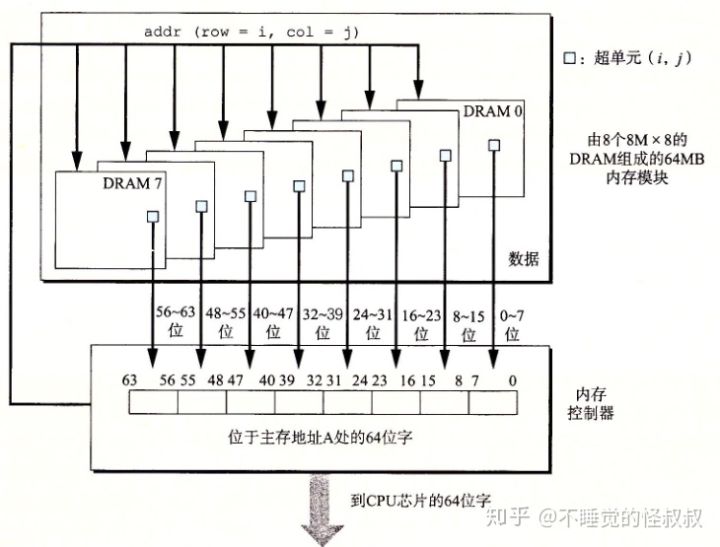
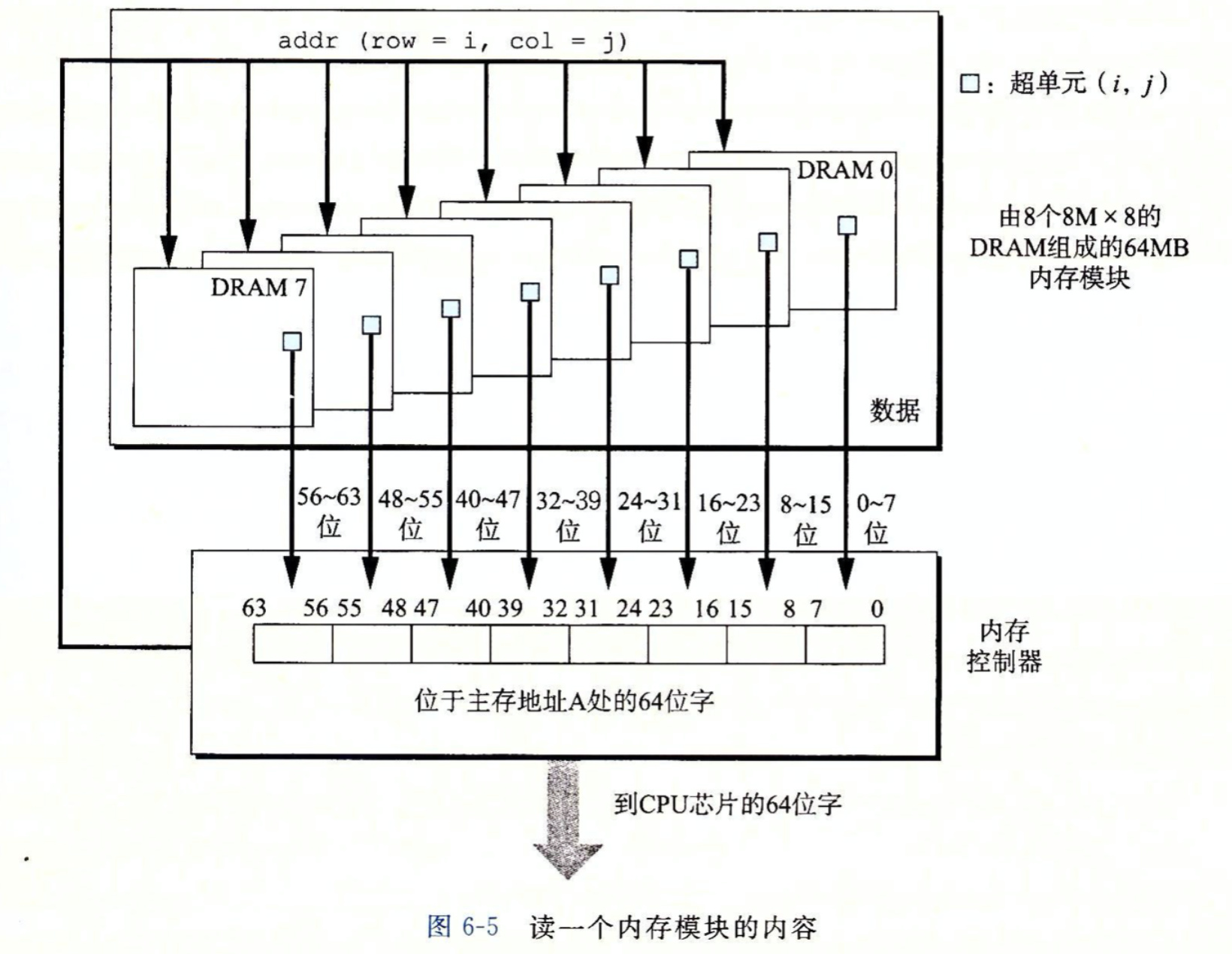
下图展示了用8个8M(超单元数) * 8(每个超单元存储一个字节)的DRAM芯片构成的内存模块,总共存储64MB(8 * 8M * 8B)。
用各个DRAM芯片中相应超单元地址都为(i, j)的8个超单元来表示主存中字节地址A处的64位字。DRAM 0存储第一个(低位)字节,DRAM 1存储下一个字节,依次类推。
要取出内存地址A处的一个字,内存控制器将A转换成一个超单元地址(i, j),并将它发送到内存模块,然后内存模块再将i和j广播到每个DRAM。作为响应,每个DRAM输出它的(i, j)超单元的8位内容。模块中的电路收集这些输出,并把它们合并成一个64位字,再返回给内存控制器。
5、增强的DRAM
一些后来发展并增强DRAM:
如果断电,DRAM和SRAM会丢失它们的信息,它们是易失的。
而非易失性存储器即使是在关电后,仍然保存着它们的信息。
只读存储器(ROM)以它们能够被重编程(写)的次数和对它们进行重编程所用的机制来区分的:
数据流通过总线在CPU和DRAM主存之间传输。这些传输的过程称为总线事务。
读事务从主存传送数据到CPU,写事务从CPU传送数据到主存。
下图是总线结构的示例图:
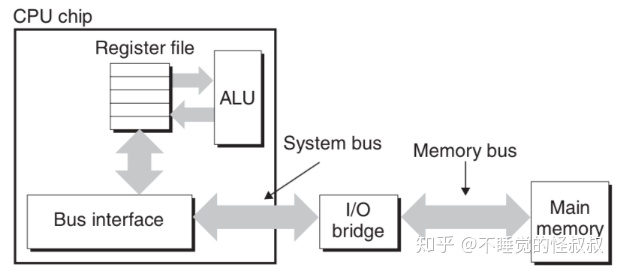
主要部件是:
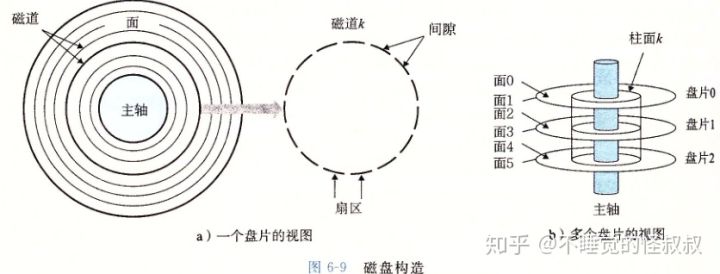
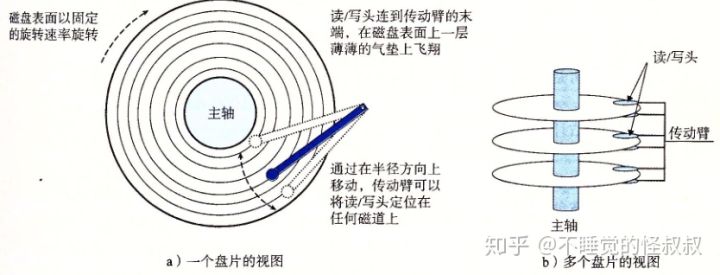
1、磁盘构造
整个磁盘驱动器通常被称为磁盘驱动器。
2、磁盘容量
一个磁盘的容量由三个因素决定:
磁盘容量的计算公式:

3、磁盘操作
对扇区的访问时间有三个主要的部分:
第四组
Helios
从CPU发送可能回到下面几个地方取数据(从慢到快):
局部性原理也是利用的缓存,分为:
在426页,多看看。
每个存储器地址有m位,形成M = 2^m个不同的地址。
一个机器的高速缓存有一下信息:
高速缓存由(S, E, B, m)组成。
以直接映射高速缓存为例:
SRAM需要的晶体管比较多,一个bit需要6~8个晶体管。相同的物理空间下,存储的数据有限,但是因为SRAM的电路简单所以访问速度快
DRAM存储一个bit只需要一个晶体管和一个电容即可,所以存储密度比较大。因为数据是存储在电容里面的,电容会不断漏电,所以需要定时刷新,这么来的动态。
DRAM的数据访问电路和刷新电路都比SRAM长,所以访问延时也比较长。
SRAM一般是CPU处理器使用,DRAM一般是内存使用。
L1缓存的是每个CPU独占,分为指令缓存和数据缓存
L2缓存也是每个CPU独占,但是不在CPU的内部会满一些
L3是多核CPU共享的缓存
第二组
可可
supercell
对内存理解有错的地方,一次访问取8块 8M *8
一个直观上感觉很有用的东西,事实上也是如此。(贪心?)
层次结构中每一层都缓存来自较低一层的数据对象,关联第一章。
我们都知道什么时候是命中,什么时候是没有命中,但是就像经常提及的LRU一样,我们应该如何去处理这些hit miss.
再想想我们真的知道什么是命中吗?如果唯一确定是否命中
再看局部性
第四组
魏琮
| 每位晶体管数 | 绝对访问时间 | 持续的? | 敏感的? | 相对花费 | 应用 | |
|---|---|---|---|---|---|---|
| SRAM | 6 | x1 | 是 | 否 | x1000 | 高速缓存存储器 |
| DRAM | 1 | x10 | 否 | 是 | x1 | 主存,帧缓冲区 |
第六组
利健锋
随机访问存储器称为 (Random-Access Memory) RAM
| 每位晶体管数 | 相对访问时间 | 是否持续 | 是否敏感 | 相对花费 | 应用 | |
|---|---|---|---|---|---|---|
| SRAM | 6 | 1X | 是 | 否 | 1000X | 高速缓存存储器 |
| DRAM | 1 | 10X | 否 | 是 | 1X | 主存,帧缓冲区 |
超单元是一个二维阵列或者说长方形阵列,由 N 行 N 列组成,行 * 列 = 当前 DRAM 芯片超单元的个数,每个超单元都有一个地址 (行, 列),我觉得可以理解成二维数组的一维索引和二维索引。
DRAM 由 N 个超单元组成,每个超单元存储了 N 位信息,所以一个超单元是 8 位的情况下,128 位的 DRAM 芯片有 16 个超单元。
每个引脚携带一个 1 位的信号,信息通过引脚这个外部链接器流入和流出芯片
每个 DRAM 芯片都连接到内存控制器,它可以一次传送或取出芯片 N 位信息
RAS 和 CAS 请求共享相同的 DRAM 地址引脚
第三组
wyhqaq
存储技术
随机访问存储器分类
磁盘访问时间
局部性
高速缓存就是为了加速程序的局部性访问,通过一种层级结构来分级访问,简单点可以类比Redis+Mysql这样的组合。
高速缓存存储器
介于CPU和主存之间,为什么会有这种存储器,主要是因为CPU和主存的访问速度之间差距过大。高速缓存存储器又分为L1、L2、L3,访问大约需要4、10、50个时间周期。
所在小组
第二组
组内昵称
文弱书生
心得体会
SRAM比DRAM更快,更贵。一般用SRAM做高速缓存存储器,用DRAM做主存以及图形系统的帧缓冲区
SRAM:将每个位存储在一个双稳态的存储单元里,每个单元用一个六晶体管电路实现
DRAM:每个位被分成d个超单元,每个超单元都由w个DRAM单元组成,一共存储dw位的信息
总线事务:每次CPU和主存之间的数据传送
读事务:
movq A, %rax 地址 A 的内容被加载到寄存器 %rax 中。发起读事务。
CPU 将地址 A 放到系统总线上。I/O 桥将信号传递到内存总线。
主存感觉到内存总线上的地址信号,从内存总线读地址,从 DRAM 中取出数据字,并将数据写到内存总线。I/O 桥将内存总线信号翻译成系统总线信号,然后沿着系统总线传递。
CPU 感觉到系统总线上的数据,从总线上读数据,并将数据复制到寄存器%rax。
写事务:
movq %rax, A 寄存器%rax 的内容被写到地址 A,CPU 发起写事务
CPU 将地址放到系统总线上。内存从内存总线读出地址,并等待数据到达。
CPU 将%rax 中的数据字复制到系统总线。
主存从内存总线读出数据字,并且将这些位存储到 DRAM 中
从磁盘读信息的时间为毫秒级,比DRAM和SRAM慢很多
磁盘容量公式:磁盘容量 = 字节数(/扇区) * 平均扇区数(/磁道) * 磁道数(/表面) * 表面数(/盘片) * 盘片数(/磁盘)
具有良好的局部性的计算机程序性能更好
确保代码高速缓存友好的基本方法:
让最常见的情况运行得快
尽量减小每个循环内部的缓存不命中数量
对局部变量的反复引用是好的
步长为 1 的引用模式是好的
所在小组
第二组
组内昵称
梁广超
心得体会
存储技术
SRAM 双稳态存储单元,DRAM动态RAM;
DRAM是由超单元军阵组成,每个超单元包含一定存储单元;
DRAM的寻址是通过单元的横纵坐标寻找,根据行坐标->取出一整行的数据->再根据列从行中取出数据;
读取内存数据时需要通过系统总线以及内存总线;
磁盘由盘面 + 柱面 + 扇区 + 磁道组成
磁盘的数据查找主要是寻道时间,估算磁盘可以使用2倍平均寻道时间进行估算
局部性
时间局部性 + 空间局部性
良好的局部性可以让程序性能良好,对于步长为k的引用模式,步长越小,空间局部性越好;
存储器层次结构
最顶端的是寄存器,cpu可以在一个时钟周期内访问到他们
存储器层次结构中的缓存
上层存储设备以下层存储设备作为缓存
每k与k+1之间都以相同大小的数据块进行传输,k与k-1又以区别于前面数据块大小的数据块进行传输;
缓存不命中的种类 冷缓存也为强制性不命中或冷不命中;冲突不命中,由于映射到相同的缓存块,导致数据被反复替换;
高速缓存存储器
主要是解决cpu和主存之间速度差距不断加大
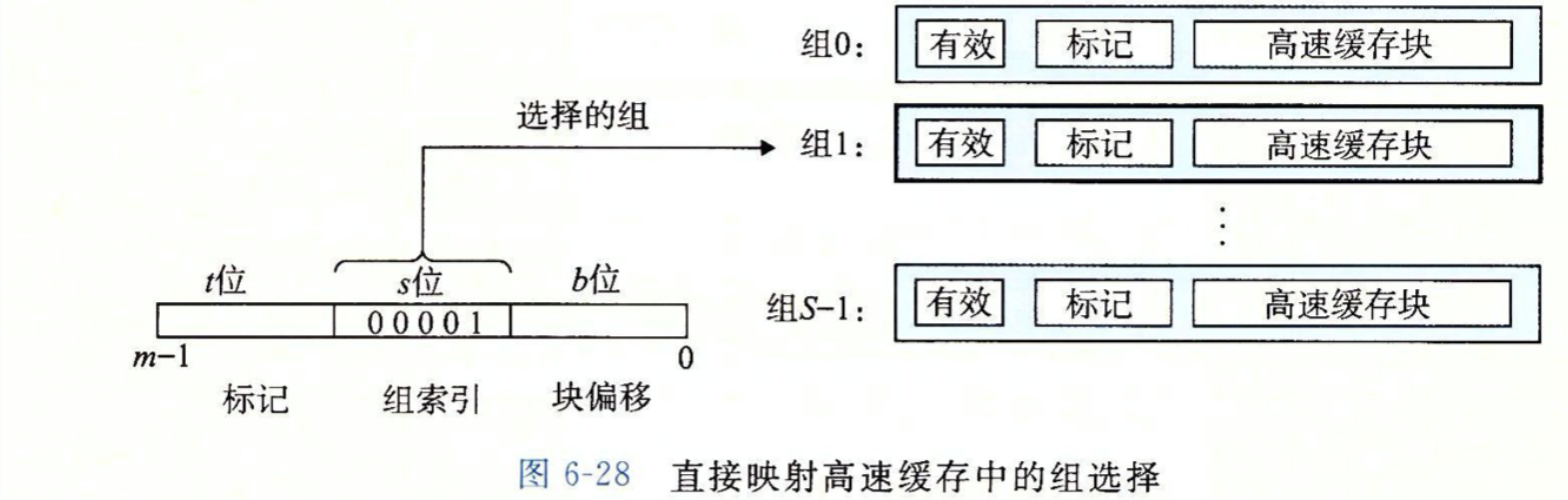
高速缓存的通用结构(S, E,B, m)
地址m 分为t = m - log2(S) - log2(B)标记位,log2(S) 组索引,log2(B)块偏移
高速缓存的写的机制
分为回写和直写
编写缓存友好的代码
让最常见的情况运行的块,既集中精力解决核心函数的循环上;
尽量减小每个循环的缓存不命中数量
第四组
Murphy
对于存储设备而言,价格,速度和容量三者并不能同时满足。所以我们便需要权衡这三者之间的重要性。而价格通常是我们无法舍弃的关键因素,所以我们所能权衡的只有容量和速度。
在权衡过程中,我们最为想要的还是希望计算机的存储设备可以容量与速度兼备,所以便使用了多种存储器相结合的存储器系统来尽量让我们的存储大量而又高效。
在存储器系统结构中,一般越“接近”CPU的存储器速度越快,容量越小,而越“远离”CPU的存储器速度越慢,容量越大。例如在CPU寄存器中的数据访问时间只需要0个周期,但却只有16个16位寄存器,总共16Byte,而如果储存在磁盘上,虽然几个T的硬盘比比皆是,但是却需要几千万个周期进行数据的读取。
我们一般希望自己跑的程序所需要的数据都存在离CPU近的地方,因为这样会极大的加强我们程序的运行速度。所以我们希望我们所使用的数据都存储在一起,用的使用只使用这些数据,这便是时间局部性和空间局部性的重要性。
另外,除了寄存器,内存和磁盘,由于CPU速度和主存的IO速度在今年不断增大,存储系统设计者又在他俩增加了高速缓存存储器,分别是L1,L2,L3,三者的容量依次增大,速度依次减慢。这三者的主要不同之处在于其结构中的cache line数量不同。数量越小,速度越快,容量越大。数量越大,速度越慢,容量越小。