sjtuhy
2020 年10 月 18 日 13:18
42
所在小组
组内昵称
心得体会
T A[N];
起始位置表示为xA,其产生了2个效果:
它在内存中分配了一个L * N字节的连续区域,L表示数据类型T的字节大小
引入了标识符A,可以用A来作为指向数组开头的指针
当我们创建嵌套数组时,如
int A[5][3];
首先创建了3个数组,每个数组容纳3个整数,假定这个数据类型称为a,然后再创建了一个数组,这个数组能够容纳5个a这样的元素,每个a元素需要12个字节来存储3个整数,整个数组的大小就是4 * 5 * 3 = 60字节
异质的数据结构
C语言提供了两种将不同类型的对象组合到一起创建数据类型的方式:
结构 :类似数组的实现,结构的所有组成部分都存放在内存中一段连续的区域中,指向结构的指针就是结构第一个字节的地址。编译器维护关于每个结构类型的信息,指示每个字段的字节偏移,它以这些偏移作为内存引用指令中的位移,从而产生对结构元素的引用
联合 :提供了一种方式能规避C语言的类型系统
sadame
2020 年10 月 18 日 13:25
45
所在小组
第一组
组内昵称
SADAME
心得体会
虽然64位系统的虚拟地址是64位来表示,但实际实现中前16位为0,所以虚拟地址最大空间为256TB
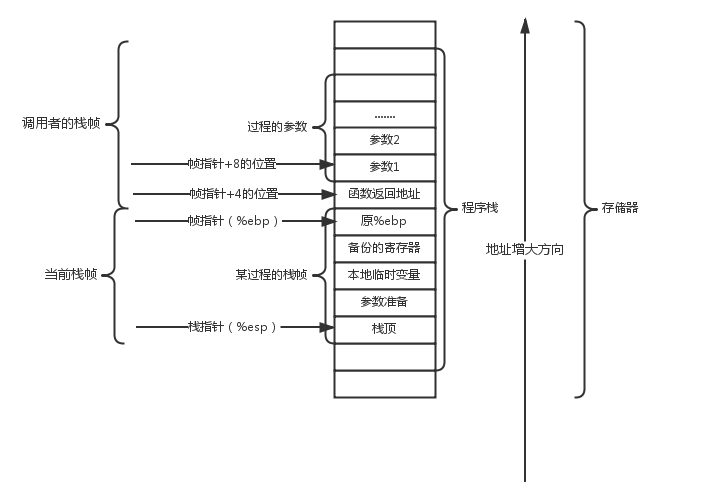
P调用Q ,首先是P的返回地址,然后是被调用保存寄存器中的值(如果要用到这种),再是P的局部变量,然后是P参数构造区(如果Q需要超过6个参数),然后是Q的返回地址,然后是Q把被保存的寄存器的值压到栈中(如果要用到),然后是Q的局部变量,再是参数构造区(递归下去。。)
理解过程中的递归运行十分关键
zzde
2020 年10 月 18 日 13:29
49
所在小组
第四组
组内昵称
张旭辉
数组的访问
一维数组的访问第i个元素 Xa+L* i 其中 Xa 是数组开头的指针,L为数组类型的大小,
嵌套数组(二维)如 D[R][C] 访问某个地址d[i][j]的方式为Xd + L(c · i +j),
用内存引用指令可以用来简化数组访问。
例如上面的例子,访问数组的第i个元素、将数组的开头指针放在rdx中即Xa, 将i放进rcx中,通知下面这个指令将i个元素的内存地址放进eax中。
movl (%rdx, %rcx, 4),%eax, 4为伸缩因子,可选的有(1,2,4,8),同理可以运用到二维数组上
数据对齐
对齐数据可以通过减少对内存的操作来显著提高内存系统的性能。对齐原则是任何K字节的基本对象的地址必须是K的倍数。
越界引用 / 缓冲区溢出
对于C语言来说、对数组的边界不进行任何检查,局部变量和状态信息都保存在栈中,会导致严重的程序错误
通过 栈随机化、栈破坏检测、限制可执行代码区域 来对抗缓冲区溢出攻击
所在小组 组内昵称 心得体会
数组:了解了C语言的数组实现方式,还可以去了解一下go的数组实现方式,研究两种实现方式生成的机器代码的差别;
第三章看起来真的挺吃力的,一遍真的不足以读懂。。
所在小组:第一组
当栈空时,再使用pop出栈
当栈满时,再使用push入栈
有可能取到栈以外未知的值,若栈段的大小为64KB,会使栈指针重新指向最后进栈的元素的地址,重新又执行指令
栈空间的大小我们要自己管理
我们要先了解运行时栈等相关的基础知识后,再去理解一个函数调用另一个函数的过程是怎么实现的。
例如函数P调用函数Q,函数Q执行完之后返回到函数P的过程:
传递控制 。简单的来说就是让CPU去不去执行P函数了,跳转的Q函数进行执行。其实汇编的处理就很简单,就是讲程序计数器设置成Q代码的起始位置就行了,接下来就会直接执行Q代码,这里要注意的是,离开P函数的时候,要记录之后P代码继续执行的位置,以便后续Q函数执行完,返回P函数的时候进行一些必要的恢复。
数据传递 。在函数调用的时候,我们还要进行必要的数据传递,包括P函数传递给Q函数的数据和Q函数执行完返回给P函数的数据。
栈上的局部存储 。我们看到的大多数过程都不需要超出寄存器大小的本地存储区域。不过有些时候需要将局部数据放在内存中。如寄存器大小不足、局部变量使用&取地址、局部变量是数组或结构的时候。除了寄存器大小不足,其他都是需要用地址的时候,会放在内存中。
递归 :递归就是自己调用自己,每一个函数调用 在栈中都有它自己的私有空间,因此同一个函数的多个未完成的调用的局部变量不会相互影响,此外栈的原则很自然的提供了适当的策略:当过程调用时,分配局部存储,当返回时,释放存储。
第三章主要讲的就是C语言一些基本功能的实现在汇编层次上是怎么做的,这一章能够让我们对机器的运作有一个相对深度的认识。
所在小组: 第五组
第四周
对抗缓冲区溢出攻击
栈随机化
栈破坏检测
限制可执行代码区域
tools
gcc
gcc
-Og 告诉编译器使用会生成符合原始C代码整体结构的机器代码的优化级别
-O1
-O2 公司常用
-S 生成 汇编代码
-c 生成 目标代码 是二进制格式的
objdump
反汇编objdump -d 可执行文件
gdb
gdb 可执行文件
(gdb) disassemble sumstore // disassemble procedure
(gdb) x/14xb sumstore // Examine the 14 bytes starting at sumstore
(gdb) bt // print stack
(gdb) run // run
(gdb) break XX // XX可以是printf main等
(gdb) n // next 下一步
(gdb) stepi
(gdb) p $rcs // 以整数值查看寄存器里面的值 或 i registers rcx
(gdb) tui enable / tui diable // 开/关 windows
(gdb) layout regs //显示通用寄存器窗口
(gdb) layout split // Display the source, assembly, and command windows.
(gdb) tui reg float // 浮点寄存器
(gdb) b // 断点
(gdb) clear number // 清楚断点 number是文件中的行号 info b 可以获取断点信息 clear 删除断点是基于行的,不是把所有的断点都删除。
(gdb) delete [breakpoints num] [range] // delete可删除单个断点,也可删除一个断点的集合,这个集合用连续的断点号来描述。
https://github.com/hellogcc/100-gdb-tips/blob/master/src/index.md
总结
结合第三章的内容和读书会第一期所思: 与二进制直接打交道的情况比较少,与16进制打交道比较多,如:java的进程号、进程地址都是16进制,socket的source IP port和 dest IP port也是16进制,还有一种更加常见strace或pref所显示的调用栈更加是16进制+机器码。还有一个很典型的core文件
所以以我看来 汇编带给我的更多是 运维排查方面的提高,毕竟直接使用汇编语言的场景还是很少的
$ cat /proc/net/tcp # 用处: 监控进程级别的网络流量,出自nethogs
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode
0: 0100007F:177C 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 3679598230 1 ffff8b3602d27440 100 0 0 10 0
1: 0100007F:177E 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 3774949553 1 ffff8afec15787c0 100 0 0 10 0
2: 0100007F:AB05 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 124722 1 ffff8b7df5ab1f00 100 0 0 10 0
3: 0A19FEA9:2426 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 487633556 1 ffff8b391aa67440 100 0 0 10 0
所在小组
静默组
组内昵称
李冲
心得体会
数组:数组的存储方式是通过分配连续内存实现的,数据内部的数据类型相同,存储的字节长度相同,访问数组的方式是通过数组首地址和偏移量及对应数据类型所占字节长度决定的。
嵌套数组:是将整个多维数组进行连续存储的,访问方式同一维数组访问方式,使用偏移量进行访问。
变长数组:C99引入功能,允许数组的维度是表达式,在数组被分配的时候才计算出来。
结构体:在内存中也是通过类似数组方式来完成的,分配一块连续的内存空间,通过首地址+偏移量来进行访问,在编译阶段完成。
数据对齐:数据对齐是为了方便系统更快地读取到对应地址的数据,提高程序读写效率,但并不会影响程序读取的行为。
指针:指针具有指针类型,并且通过&运算符创建和*运算符进行指针的引用。
binwu
2020 年10 月 25 日 15:09
57
所在小组
第六组
组内昵称
吴彬
你的心得体会
代码的局部性问题
int sum(int a[M][N]) {
int i, j, sum = 0;
for (i = 0;i < M;i++) {
for (j = 0;j < N; j++) {
sum += a[i][j];
}
}
return sum;
}
局部性良好
int sum(int a[M][N]) {
int i, j, sum = 0;
for (j = 0;j < N; j++) {
for (i = 0;i < M; i++) {
sum += a[i][j];
}
}
return sum;
}
局部性不好
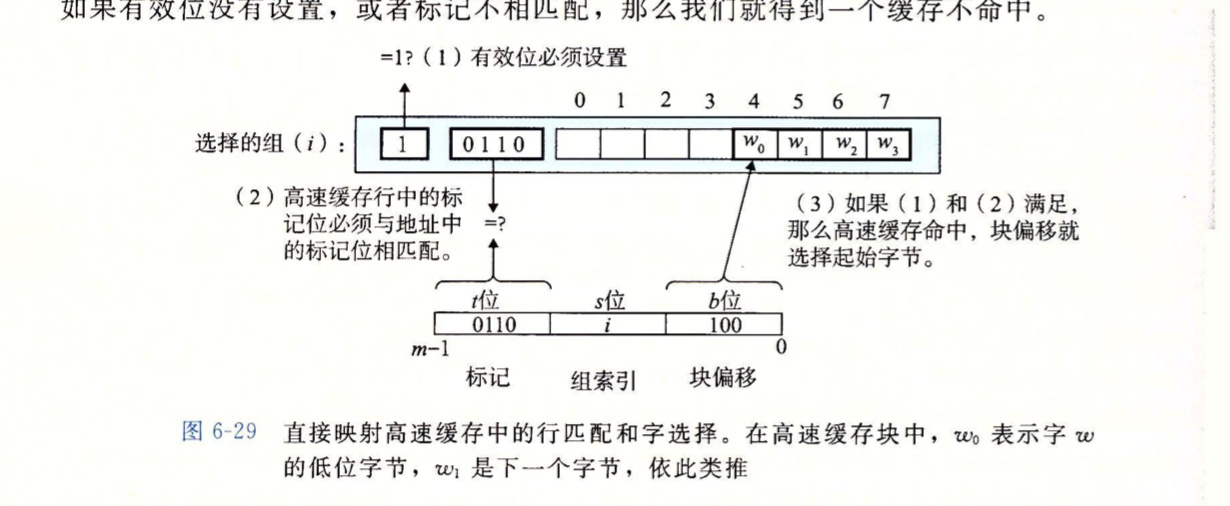
高速缓存映射公式
在阅读第三版第12章12.5.4节的生产者-消费者问题时,图12-25所示的一部分代码如下所示