第四周打卡情况
第一组:
Liam、bluewhale
第三组:
MrTrans
第五组:
肖思成
第七组:
K、陈盛华
静默组:
维钢、hellolinux
共计:8 人未打卡
请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:
所在小组
第一组
组内昵称
张三
你的心得体会
可以基于不同知识点进行,有更新请在原回贴更新,每人每周只发一个帖子
一段自己的阐述
第二段自己的阐述
…
第四周打卡情况
第一组:
Liam、bluewhale
第三组:
MrTrans
第五组:
肖思成
第七组:
K、陈盛华
静默组:
维钢、hellolinux
共计:8 人未打卡
请大家以回帖的方式将你在共读第一周的心得体会用你自己的话表达出来。
样例:
第一组
张三
可以基于不同知识点进行,有更新请在原回贴更新,每人每周只发一个帖子
…
第七组
杨文
第三章“程序的机器级表示”看起来真的非常吃力,汇编知识完全都忘记了,我都不好意思说自己是计算机系的,回忆当初学编译原理的时候,肯定是觉得没啥用,没有认真学,现在知道吃亏了,根本看不懂。
印证了那句话,每个字都认识,但是连起来就不懂是啥意思了。
如有同感,请给个红心![]()
影响对浮点数据操作的程序如何被映射到机器上
通过某种寄存器方式来完成。
第六组
黄永平
用条件传送来实现条件分支,完美避免了因为分支可能带来的性能问题(需要清空流水线)。但是条件传送指令也有一些受限条件:
a、因为会把两个分支的运算都提前算出来,如果两个分支都涉及大量计算的话,就得不偿失了,所以需要分支中的计算尽量简单。
b、涉及指针操作的时候,如 val = p ? p : 0;,因为两个分支都会被计算,所以可能导致奇怪问题出现
c、如果分支中的计算是有副作用的,比如 val = x > 0 ? x= 7 : x+= 3;
由于变长参数n的可变性,因此必须引入乘法。动态的版本必须用乘法指令进行伸缩,而不能用一系列的移位和加法。因此,变长数组会引入性能问题。
通过对齐数据可以提高内存系统的性能。对齐原则是任何K字节的基本对象的地址必须是K的倍数。
通过缓冲区溢出,我们可以在程序返回时跳转到任何我们想要跳转到的地方,攻击者可以利用这种方式来执行恶意代码。
1、栈随机化 2、栈破坏检测 3、限制可执行代码区域
第二组
Joey
面向过程风格编程(函数调用,函数的局部存储等功能)的支持是由机器级语言的实现的,函数的调用规约包括一些资源使用的约定规则(Caller Save和Callee Save、栈空间的布局、寄存器使用规则等)
局部变量和传参在数目较小的时候都可以直接通过寄存器来实现(当然如果局部变量是数组或者结构体肯定是不行的)。但是如果寄存器不够用了或者需要使用到局部变量的地址,就必须分配到栈帧上面,动态访问是通过%rsp栈顶指针的偏移来实现的。这里有一个思考,考虑到访问寄存器的速度比访问内存要快很多,一个函数的局部变量数目较少的时候,是否执行效率更高?(待验证)
将寄存器分为Caller Save和Callee Save两类的目的(个人理解):因为寄存器是Caller和Callee的共享资源,举个例子,在Callee指令执行的时候,coder并不清楚例如%rbx这样的寄存器中的数据到底能不能随便改,会不会里面已经存了Caller的局部变量?会不会Caller已经对其做了备份,在Callee执行ret之后会将寄存器的原值恢复?所以将寄存器分为这样的两组,告诉Callee哪些寄存器是可以信任的,可以随便改,反正Caller会在Callee结束后自动恢复原值,哪些Callee在修改之后,必须在ret之前自己将其恢复。但是要解决这样的问题可以很简单,就是让Callee信任所有寄存器或者一个也不信任,但是不这样设计的原因猜测是为了效率考虑?因为毕竟Caller也不一定非要使用所有的寄存器,将他们全部保存再恢复实属效率上的浪费。
递归实际上在机器级上的实现就是普通的函数调用
通用寄存器不能存储浮点数,浮点数的存储有专用的XMM寄存器,计算、转换和比较也有专有的指令,而且这个体系看起来还不小。之前看过腾讯的libco的协程上下文切换默认是不切换浮点数上下文的(也就是说协程的上下文里无法正常使用CPU浮点的能力),现在看起来应该是为了协程切换的效率考量。
第四组
Helios
数组A[i]和*(A + i)是一样的,当时有困惑,为什么会是一样的呢为什么没有乘类型的size呢,就写了下面的程序,当然也是习题的程序。
#include <stdio.h>
int main()
{
char a = '0';
char *aa = &a;
int *b = (int*)aa + 7;
int *c = (int*)(aa + 7);
printf("%d, %d, %d\n", c, b, aa);
return 0;
}
上面代码输出:
-2007374258, -2007374237, -2007374265
后来差了一下,原来加size(类型)这一步是GCC编译器给加上的。
那为什么指针是无状态的,但是有知道类型的size呢,原来指针步长是在编译器阶段就做好的了。https://www.zhihu.com/question/54785331
还有一个概念是RTTI,泛型啥的都是依靠这个动态类型识别做的。
数据对齐主要为了下面两点:
浮点操作就是记住参数的寄存器的顺序即可,还有就是指令的名字太难记了…
第三组
hy
不同的数据类型字节长度不同,对应到数组就有不同的长度,不同数据类型数据的长度不同,但访问的方式类似,都是通过首地址 + 偏移 * 每个数据的大小访问。
多维数组的结构类型,会分配整个多维数组需要的空间。
数据类型在内存中需要对齐,因为内存访问通常都是 4 或 8 个字节为单位,不对齐的情况下,访问效率不高。
结构体占据的内存空间必须是最大的类型所需字节的倍数,好的布局方式可能会占据更少的空间,节省不少内存。
进程的运行时栈从上往下生长,有 8MB 的大小限制,而栈再往上是另一个程序的内存范围,通过输出超长的数据,可以非法的修改内存,覆盖栈上的返回地址,精心构造内容,跳到一个想要的任意地址执行恶意代码(缓冲区溢出)。
避免缓冲区溢出有几种思路:
写好代码,不使用危险的函数;
提供系统层级的保护,栈随机化,每次执行程序时栈的位置不确定,不能精准定位地址;
使用认证机制,栈破坏检测,在超出缓冲区的位置加一个特殊的值,如果发现这个值被改变,就知道溢出了;
限制可执行代码区域。
感觉浮点数的处理是一个大难题,既不能精确表达,为了提升浮点数的计算速度又增加了很多 Hack 指令。
Java 实现的思路非常有意思 Java 代码编译成特殊的二进制 Java 字节代码,是一种中间格式,通过**软件(虚拟机)**翻译给硬件执行,这样只要实现不同平台上的翻译软件(虚拟机),就能实现跨平台。
第七组
吴奇驴
这两周基本都是说的C语言的程序机器码表示和相关指令操作,那其他语言又是怎么做的呢?
解释性语言是怎么做的?还有语言里面“值传递”和“引用传递”问题。
静默组
Han
变长数组的索引思路的优化逻辑也很清楚,目标是避免乘法逻辑的地址计算导致可能的性能损耗
对于struct,实际在内存是以类似数组的方式,分配了一块连续的内存,访问字段是通过地址的偏移计算来完成的,这个过程是在编译阶段就完成了,编译好的机器代码中并没有关于字段的定义逻辑。
数据对齐的原则:
指针和一维数组可以理解是一样,其寻址的逻辑是一样的。当数组变成多维时,下面这两个就有区别了:
int **ipp; // 指向int指针的指针
int (*parr)[10]; // 指向列数为10的数组指针
第五组
陈松彬
Author: @陈松彬
Date: 2020-10-18
section2 主要是3.8 ~ 3.12
书中给出的公式:对于数组T D[R][C],元素D[i][j]的内存地址为&D[i][j] = 数组起始地址 + i * C + j
贴出书中一个例子:
# define N 16
typedef int fix_matrix[N][N]
// 计算矩阵A的第i行跟 矩阵B的第k列 的向量积
int fix_prod_ele(fix_matrix A, fix_matrix B, long i, long k) {
long j;
int result = 0;
for (j=0; j<N; j++){
result += A[i][j] * B[j][k];
}
return result;
}
按照我们写的代码:每次循环总共会有3个乘法操作:
不使用gcc优化:
gcc -Og -S fix_prod_ele_opt.c -o Og.s
使用gcc优化:
gcc -O1 -S fix_prod_ele_opt.c -o o1.s
优化过后汇编代码:
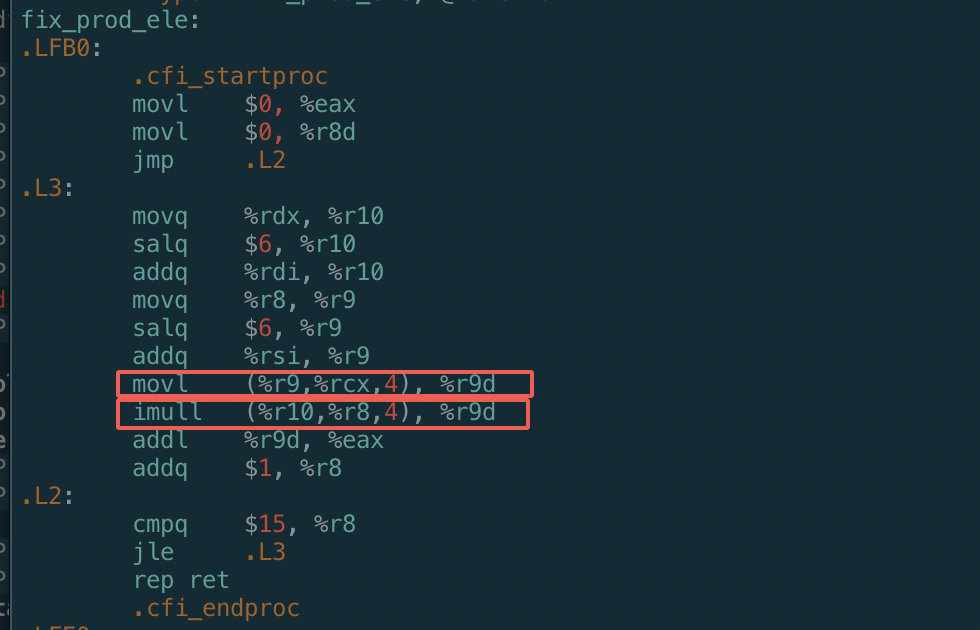
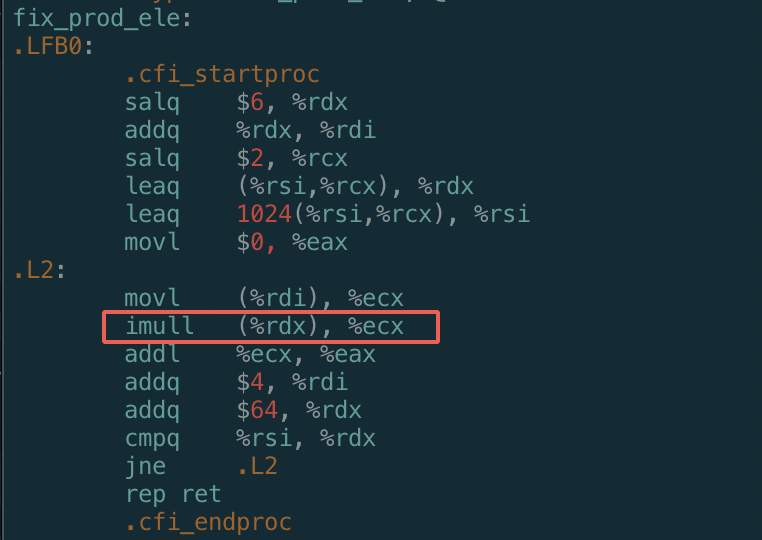
a) 我们可以看到循环只用了一个乘法指令
b) 可以看到对于数组元素访问,本来是需要用到乘法计算数组元素地址的,结果都被GCC优化掉了,改成通过将地址加一个常量:
c) 再次证明乘法操作是比较耗时的,GCC编译器会千方百计减少乘法操作
地址必须是某个值K的倍数,这个K
为什么需要内存对齐:提高CPU从内存获取数据的效率
应用:
a) 利用内存对齐,通过对结构体中的某些字段的顺序进行重新排序,可以减少padding,进而使得一个结构体占用的内存减小。
b) 这个优化貌似编译器不会帮我们做,我们可以写一个脚本,可以对我们的定义的结构体的字段进行重新排序。这个算法也很简单,只要把占用字节数多的字段排在前面即可。
c)比如
# 16字节
type TestStruc struct {
A int # 0
B char # 4
C int # 8
D char # 12
}
# 12字节
type TestStruc struct {
A int 0
C int 4
B char 8
D char 9
}
疑问1: 对于一个指令movb 内存,到寄存器;是如何传输的?
猜想:
(1)CPU执行指令,movb 内存地址,某个寄存器
(2)根据内存地址 找CPU cache 【这个是如何映射的?】
(3.1 )如果命中CPU cache
(3.2) 如果没有命中CPU Cache,从内存加载数据到CPU Cache
疑问2: 对于读下面中蓝色的8字节数据:
a) 为什么要执行两次内存操作(1)0-7(2)8-15
b) 为什么不能一次性搞定:3-10
静默组
Tang_D
大家在阅读之余可以尝试去做一下csapp的lab,相信会收获不少
1.在指针运算时,我们写的x+i,在汇编中的公式实际上是x+Pi P是数据的长度,而对于多维数组在内存中的存储来说,是行优先,也就是根据行的顺序,一个个存放,D[i][j] = D+L(Ci+j) L是以字节为单位的数据大小
2.对于定长数组,一般编译器会进行优化,也就是先得到数组结束的地址,再判断是否循环终止
3.变长数组则是用一个寄存器存储变量
4.C中的struct每个元素按照所占字节大小,一个个分配,有时为了地址对齐,会填充空间,而union则是所有的元素占据一块地址,可以用来判断计算机是小端还是大端。
5.对于缓冲区的溢出,可能修改了栈中的内容如返回地址等,可以通过金丝雀(某一个位置放置一个数字,检查数字是否被修改,检测栈破坏,或者随机化来避免栈攻击)
第三组
wyhqaq
1.数组分配与访问
假设有int数组声明E[i], E的地址在%rdx中, i在%rcx中
2.结构
指向结构的指针是结构第一个字节的地址,结构的所有组成部分都存放在一段连续的内存中, 可以计算偏移量来访问所有字段
3. 数据对齐
编译器会在未对齐的结构体中插入一些空间来满足数据对齐规则
4. 内存越界和缓冲区溢出
对越界的内存写值可进行缓冲区溢出攻击(修改栈中的返回地址)
对抗缓冲区溢出攻击:栈随机化,栈破坏检测,限制可执行代码区域
第二组
陶鑫
学习汇编对程序员有什么作用?答:了解底层运行原理,可以提高代码的运行效率。https://purewhite.io/2020/10/14/manual-intelligence-optimize-golang-compiler/
### 所在小组
第五组
锦锐
This is a difficult chapter I have encountered so far ! not only requiring us to read the book again and again, but also we need to run the assembly code in machine . For my own opinion, this chapter can be break down into a few topic below. we much know the levels of abstraction of different code
第二组
可可
The alignment rule is based on the principle that any primitive object of K bytes must have an address taht is a multiple of K.
point to the address of the value
指针总以为自己懂了,但是总感觉有点迷,没那么透彻。
该书把指针罗列了下
every pointer has an associated type。
void * type represents a generic pointerevery pointer has a value
& and *
神奇的知识点增加了 之
leaq,之前看leaq的时候总是弄不明白。
leaq在3.5算术和逻辑运算章节,因为leaq不解引用,直接操作地址。那么他也就可以用于常规的数值运算。
其次在我们指针的时候,他就特别有用。
arrays and pointers are closely related
a[3] = *(a+3)
a+3 = pa + sizeof(a) * 3
casting from one type of pointer to another changes its type but now its value.
pointers can also point to functions
???连续的栈中有连续的数据
不做任何防护的话 我们可以根据栈的起始访问到不应该访问的数据
还记得学OS的时候,老师课堂上随口提到程序攻击后 底下那一张张放光的眼睛。
stack randomization
stack coprruption detection
a canary hh
limiting executable code regions
flag for RWE
栈的长度,为什么固定,为什么变长?? 其所以然还是不懂
关于寄存器最开始接触的时候就在想为什么这么命名,本身看着规律性不强,如果可以知其所以然,那么可能对记忆有所帮助。
16个寄存器命名由来
最初的8个,AX,BX,CX,DX,SP,BP,SI,DI
其中 里面的X是占位符,代表 H或者L。
后面扩展了新的8个,统一命名 R8~R15
原8个含义
除此之外,图片里还有一个后缀标志大小。
原有8个寄存器
byte: al(low), r8b(byte)
word: ax,r8w(word)
double word: eax(extend),r8d(double word)
long: rax(r register), r8(origin raw)
所在小组
第二组
组内名称
文弱书生
心得体会
本周学习从数组的分配和访问方法开始,
连续内存,起始地址为Xa,元素i会存放在Xa+L·i 的地方
并且学习了&和的区别,这一点之前一直很迷
&——指针,——间接引用指针
随后是数组的嵌套,对二维数组元素的内存地址有了基本的概念
二维数组的大小为 类型大小 Lt * i * j
数组元素在内存中按照“行优先”的顺序排列
访问多维数组的元素,编译器会以数组起始为 基地址,偏移量为索引。
对于一个如下数组:T D[R][C] 它的数组元素D[i][j]的内存地址为, &D[i][j] = xD + L(C · i + j)
对于结构和联合的关系和区别,在此之前一直以为只是形式上有所不同,现在知道了具体的区别是对象的引用不同,从而占用内存大小也会有所区别
struct S3 {
char c;
int i[2];
double v;
}
struct U3 {
char c;
int i[2];
double v;
}
类型 c i v 大小
S3 0 4 16 24
U3 0 0 0 8
学习了C语言中内存对齐的基本概念和方法
某种类型对象的地址必须是某个值K(通常是2、4、8)的倍数。
常用的gdb命令,对于工作中也非常实用,可以追踪数据内存变化,通过断点查看程序是否按照意愿在执行
最后简单学习了内存越界等涉及安全方面的知识,以及如何对抗缓冲区溢出的攻击
栈随机化
栈破坏检测
限制可执行代码区域
第七组
高华
第三章读起来非常吃力,但读下来还是有很多收获的,还需要再多读几遍才行。
指针是C语言的核心,是做着对内存的抽象,方便程序员直接操作内存,在汇编语言中并无特殊性。了解指针和它对应的汇编代码,对于彻底理解指针有很大的帮助。
第六组
之昂
上周第三章已经看完,因此这周选择了加看第五章优化程序性能,通常编译器可以代替我们进行程序优化,例如循环展开、代码移动等。但是由于函数存在编译器无法感知的副作用,往往还需要程序员在编写代码时注重效率。
一些看上去无足轻重的代码段可能隐藏着渐进低效率(asymptotic inefficiency),在数据量小时测试可能无法发现问题,但部署环境后代码会突然成为瓶颈。有经验的程序员工作的一部分就是避免引入这样的渐进低效率。
比如在循环中止条件我们经常会用到 strlen(s)来作为循环中止条件,而strlen所需时间和字符串长度N成正比,如果每次循环迭代前都判断一次,那么循环的整体运行时间会是N*N。此时我们如果将字符串长度提前进行计算,再进行循环判断就会显著提升性能。书中实现对1048576字符进行测试,循环运行时间从17分钟降低到2毫秒,50W倍左右的提升。
当前GCC版本会对整数运算执行重新结合,但不是总有好的效果,通常循环展开和并行地累计在多个值中是提高程序性能的更可靠的方法。
CPE Cycles Per Element,作为一种表示程序性能并指导我们改进代码的度量标准。可以帮助我们在更细节的级别上理解迭代程序的循环性能。
未经优化的代码通常效率比较低,简单地使用命令行选项就能显著地提高程序性能(超过两个数量级)。
代码移动,识别要执行多次(如循环内)但是计算结果不会改变的计算,将其移动到代码前不会多次求值的部分来提高性能。优化编译器会尝试进行代码移动,但是不能可靠地发现一个函数是否会有副作用。因此为了改进代码,程序员必须经常帮助编译器显示地完成代码移动。
过程调用会带来开销,而且妨碍大多数形式的程序优化。
尽量消除代码中不必要的内存读写,用寄存器来保存中间值来提升性能
要进一步提高性能,必须考虑利用处理器微体系结构的优化,也就是处理器用来执行指令的底层系统设计。要想充分提高性能,需要仔细分析程序,同时代码的生成也要针对目标处理器进行调整。
循环展开,通过增加每次迭代计算的元素数量,减少循环的迭代次数。编译器可以很容易地执行循环展开,只要优化级别设置得足够高。GCC -O3就会执行。
提高并行性:
其他一些制约程序在实际机器上性能的因素:
总结来说,优化程序性能的基本策略如下:
第七组
李佳