《Go 语言并发之道》读后感目录
- 《Go 语言并发之道》读后感 - 第一章
- 《Go 语言并发之道》读后感 - 第二章
- 《Go 语言并发之道》读后感 - 第三章
- 《Go 语言并发之道》读后感 - 第四章
- 《Go 语言并发之道》读后感 - 第五章
前两章我们介绍了并发之苦,CSP 理论。这一章作者详细的介绍了 Go 是如何支持并发的。
goroutine
goroutine 是 Go 语言程序中最基本的组织单位之一。每个 Go 语言程序至少有一个 goroutine: main goroutine , 它在进程开始时自动创建并启动。我们经常听人说到 goroutine ,那它究竟是什么呢?
- goroutine 是一个并发的函数。
- goroutine 是协程,非系统线程,非绿色线程。
goroutine 并没有定义自己的暂停方法或再运行点。Go 程序的 goroutine 调度机制决定,当 goroutine 阻塞的时候自动把它挂起,然后在它们不被阻塞时恢复它们。在 gouroutine 阻塞的时后会触发抢占。
上述这种托管机制是一个名为 M:N 调度器的实现,这意味着它将 M 各绿色线程映射到 N 个系统线程。然后 goroutine 运行在绿色线程上。当我们的 goroutine 数量超过可用的绿色线程时,调度程序处理分布在可用线程上的 goroutine,并确保这些 goroutine 被阻塞时,其他 goroutine 可以运行。
Go 语言遵循 fork-join 的并发模型:
- fork 指程序在任意节点,可以将子节点于父节点同时运行
- join 将来在某个节点时,分支将会合并在一起
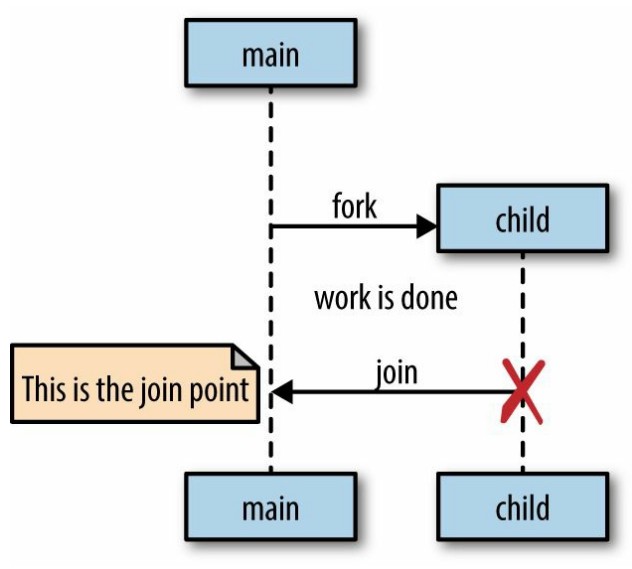
我们一起来看一个例子:
var wg sync.WaitGroup
sayHello := func(){
defer wg.Done()
fmt.Println("hello")
}
wg.Add(1)
go sayHello()
wg.Wait()
fmt.Println("bye")
这里我们引入了,sync 用作同步,wg.Add() 到 wg.Wait() 定义了一个临界区。临界区内的操作完成后,才会继续下面的 fmt.Println(“bye”)
轻如鸿毛
内存
开辟一个新的进程,或线程都需要消耗系统的资源。开辟一个线程需要消耗大概 8 MB资源,通过下面的命令,可以查看:
ulimit -s
在上一章结尾的我写到可以认为 goroutine 是没有任何代价的,下面我们来看一个例子,以下内容会开启空的 goroutine :
memConsumed := func() uint64{
runtime.GC()
var s runtime.MemStats
runtime.ReadMemStats(&s)
return s.Sys
}
var c <-chan interface{}
var wg sync.WaitGroup
noop := func(){ wg.Done(); <-c }
const numGoroutines = 1e4
wg.Add(numGoroutines)
before := memConsumed()
for i := numGoroutines; i > 0 ; i--{
go noop()
}
wg.Wait()
after := memConsumed()
fmt.Printf("%.3fkb",float64(after - before) / numGoroutines /1000)
Windows 10 下的执行结果:

Linux CentOS 7.4 下的执行结果:

上下文切换
taskset -c 0 perf bench sched pipe -T
# 如果你的机器没有安装 perf ,可以用如下命令
yum install perf
apt install perf
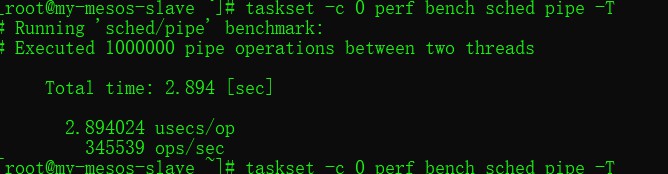
goroutine 上下文切换
func Ben(b *testing.B) {
var wg sync.WaitGroup
begin := make(chan struct{})
c := make(chan struct{})
var token struct{}
sender := func() {
defer wg.Done()
<-begin
for i := 0; i < b.N; i++ {
c <- token
}
}
receiver := func() {
defer wg.Done()
<-begin
for i := 0; i < b.N; i++ {
<-c
}
}
wg.Add(2)
go sender()
go receiver()
b.StartTimer()
close(begin)
wg.Wait()
}

我们可以看到上下文切换,线程需要花费 2s 左右的时间,goroutine 上下文切换只需要 0.002s。
sync
sync 包包含对低级别内存访问同步最有用的并发原语,
WaitGroup
当你不关心并发操作的结果,或者你有其他方法来收集它们的结果时,WaitGroup 是等待一组并发操作完成的好方法。
var wg sync.WaitGroup
wg.Add(1) // 参数为 1 ,表示一个 goroutine 开始了
go func() {
defer wg.Done() // 退出前执行 Done 操作,我们向 WaitGroup 表明我们已经退出了
fmt.Println("1st goroutine sleeping...")
time.Sleep(1)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(2)
}()
wg.Wait() // 等待所有 goroutine 都执行完,再继续下面的逻辑
fmt.Println("All goroutines complete.")
互斥锁和读写锁
Mutex 是 “互斥” 的意思,是保护程序中临界区的以重方式。它提供了一种安全的方式来表示对这些共享资源的独占访问。
var lock sync.Mutex
n := 1
plus := func(){
lock.Lock() // 加锁
defer lock.Unlock // 函数执行完成释放锁
n++
fmt.Println("plus n =>",n)
}
subtr := func(){
lock.Lock()
defer locl.Unlock
n--
fmt.Println("subtr n =>",n)
}
go subtr()
go plus()
fmt.Println(n)
Mutex 互斥锁,对临界区强限制,goroutine 必须先获得锁然后再进行临界区操作。
有的时候我们希望下游读取临界区操作可以并发,以便提升代码读操作的性能,毕竟一旦加锁整体都需要等待锁释放,如果 Lock() 和 Unlock() 之间的逻辑阻塞,大家都的等待。RWMutex() 就应运而生了。
var rwLock sync.RWMutex
// 获取锁,读写锁,其他 goroutine 不可对临界区内容进行读写操作
rwLock.Lock()
// 释放锁
rwLock.Unlock()
// 获取读锁,限制其他 goroutine 写,但不限制读
rwLock.RLock()
// 释放读锁
rwLock.RUnlock()
sync.NewCond
在 Golang 源码中很好的描述了,cond 类型的用途:
一个 goroutine 的集合点,等待或发布一个 event。
使用方式如下:
c := sync.NewCond(&sync.Mutex{})
c.L.Lock()
for !condition(){
c.Wait()
}
c.L.Unlock()
sync.Once
sync 包为我们提供了一个专门的方案解决一次性初始化的问题: sync.One。
使用方式如下:
var count int
increment := func(){
count++
}
var once sync.Once
var increments sync.WaitGroup
increments.Add(100)
for i := 0; i < 100; i++{
go func(){
defer increments.Done()
once.Do(increment)
}
}
increments.Wait()
fmt.Println("Count is %d \n",count)
sync.Pool { }
Pool 池 是并发安全实现。用于约束创建昂贵的场景,例如: 链接 Redis,MySQL,或其他调用远端服务的时候。只创建固定数量的实例,保障对端服务可用。
myPool := &sync.Pool{
New: func() interface{} {
fmt.Println("Create new connection")
return struct{}{}
},
}
instance := myPool.Get() // 获取实例
....
myPool.Put(instance) // 释放实例,供其他人使用
当你使用 Pool 工作是,记住以下几点:
- 当实例化 sync.Pool,使用 new 方法创建一个成员变量,在调用时时线程安全的。
- 当你收到一个来自 Get 的实例时,不要对所接收的对象的状态做出任何假设。
- 当你用完一个从 Pool 中取出来的对象时,一定要调用 Put,否则,Pool 就无法复用这个实例了。通常情况下,这是用 defer 完成的。
- Pool 内的分布必须大致均匀。
channel
channel 是由 Hoare 的 CSP 派生的同步原语之一。
// 定义双向 channel
var ds chan interface{}
ds = make(chan interface{})
// 定义 只读 channel
var or <-chan interface{}
or = make(<-chan interface{})
// 定义只写 channel
var ow chan<- interface{}
ow = make(chan<- interface{})
// 创建缓冲 channel。
bufferChan := make(chan interface{} ,4)
goroutine 是被动调度的,没有办法保证它会在程序退出之前运行。Go 语言中的 channel 是阻塞的,这样在不同的 goroutine 操作同一个 channel 的时候就会被 channel 阻塞,我们还需要注意,不要试图从一个空 channel 中读取数据,如果只读取将会触发死锁,读数据的 goroutine 将等待至少一条数据被写入 channel 后才行。
个人对于缓冲 channel 的一些看法
- 当生产者速度远大于消费者速度,创建缓冲 channel 是一种正向优化
- 当消费者具有阻塞性质或 syscall 时(例如:数据写入磁盘,请求外部接口,远端服务)
- 当消费者速度大于生产者速度,消费者侧无阻塞性质,设置缓冲 channel 可能是一种负优化
对于只读只写 channel 的一些个人经验:
我们的函数往往是一层一层的调用的,当我们需要使用 channel 构建并发的时候,我们需要知道当前操作的函数对需要操作的 channel 是生产者,或消费者。这样构建时就可以防止一些死锁,channel 未关闭的问题。这是我个人的使用经验。
prod := func(n chan<- int){
defer close(n)
n <- 1
}
consum := func(n <-chan int) <-chan int{
m := make(chan int)
tmp := <-n
fmt.Println(tmp)
go func(){
defer close(m)
m <- tmp
}()
return
}
num := make(chan int)
go prod(num)
mm := consum(num)
for i := range mm{
fmt.Println(i)
}
从上方的代码段可以看出一些技巧
- channel 的输入向都需要一个 goroutine.
- 在 consum 函数内部定义 channel 返回一个只读 channel ,有效的管理了临界区
- 全局定义的 num ,在传入 函数时转换了性质,防止在一个 goroutine 种对同一 channel 既读又写
这里要说明一下单向 channel 无法向双向 channel 转换,双向channel 可以向单向 channel 转换。
channel 状态机
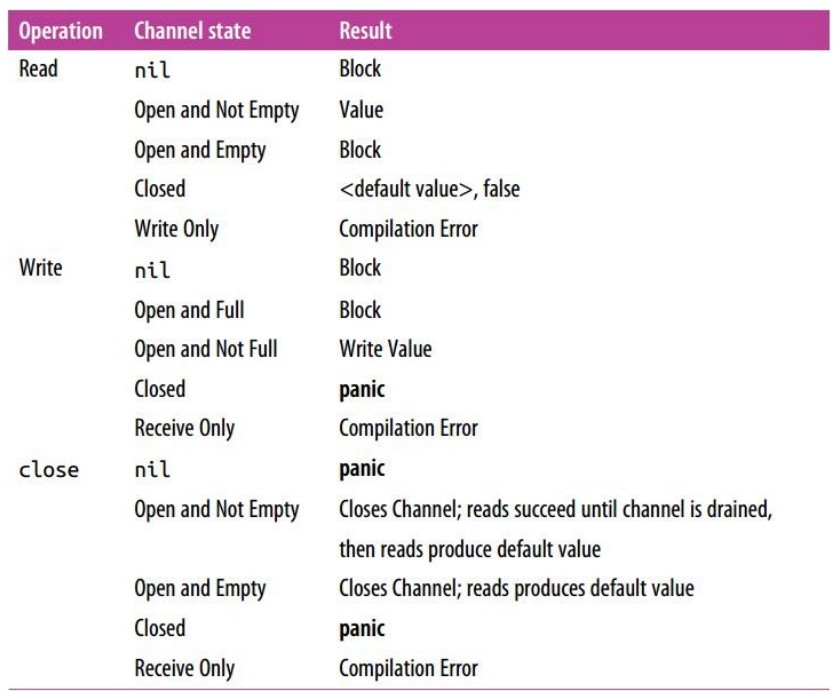
从 channel 的所有者说起。当一个 goroutine 拥有一个 channel 时应该:
- 初始化该 channel
- 执行写入操作,或将所有权交给另一个 goroutine
- 关闭该通道
- 将此前列入的三件事封装在一个列表中,并通过订阅 channel 将其公开
通过将这些责任分配给 channel 的所有者,会发生一些事情:
- 因为我们是初始化 channel 的人,所以我们要了解写入空 channel 会带来死锁的风险
- 因为我们是初始化 channel 的人,所以我们要了解关闭空 channel 会带来 panic 的风险
- 因为我们是决定 channel 何时关闭的人,所以我们要了解写入已关闭的 channel 会带来 panic 的风险
- 因为我们是决定何时关闭 channel 的人,所以我们要了解多次关闭 channel 会带来 panic 的风险
- 我们在编译时使用类型检查器来防止对 channel 进行不正确的写入
作为一个消费者,需要只需要担心两件事:
- channel 什么时候会被关闭
- 处理基于任何原因出现的阻塞
Select
channel 将 goroutine 粘合在一起,让我们构建起一条非常健壮,高性能的生产线。那么程序中有多条生产线,select 语句就是帮我们多个 channel 组合在一起。
// 一起看一下 select 的用法
var ca,cb,cc <-chan interface{}
var cd chan<- string
select {
case <- ca:
// 业务逻辑
case <- cb:
// 监控逻辑
case <- cc:
// 告警逻辑
case cd <- "Hello Sober":
// 佛系逻辑
}
关于 select-case 调度疑问
乍一看 select 于 switch 类似根据不同 case 判断并执行逻辑。 我们知道既然是 channel ,那么一定是有数据需要传递的,不能简单的条件判断而已,例如我想让 cb 执行需要什么条件呢?其实 select 内部实现一种均衡调度,保证每个 case 都会被执行,所有 case 执行次数相对均衡,你可以用如下代码测试一下:
c1 := make(chan int)
close(c1)
c2 := make(chan int)
close(c2)
var c1n ,c2n int
for i := 100; i > 0; i-- {
select {
case <- c1:
c1n++
case <- c2:
c2n++
}
}
fmt.Printf("c1n: %d \nc2n: %d\n",c1n,c2n)
如何关闭已经我们认为已完成的工作流?
我们来看这个例子,让我们记住它,这将是高并发程序的核心一环,并发控制的根基:
var c <-chan int
select {
case <- c: // 这里我们干一件愚蠢的事,从空的 channel 中读取数据,如果没有 select 它将触发死锁,在select 中他将永远不被执行
case <-time.After(1*time.Second): // 1秒后关闭整个工作流
fmt.Println("The pipeline is end")
}
默认值
select {
case <- c1:
// 神鬼逻辑
case <- c2:
// 鬼神逻辑
default:
fmt.Println("没有可用的 channel,触发默认操作 ....")
}
永久阻塞
select {}
GOMAXPROCS 控制
这里需要提一下 GMP 模型,M 就是 GOMAXPROCS 的配置,通常为当前计算节点最大 OS 线程数。
// 由 runtime 包控制
runtime.GOMAXPROCS(runtime.NumCPU())
结束语
虽然是第三章,但是我认为这是全书技巧篇第一章,接下会有更精彩的技巧,例如:如何构建一个 pipeline ;如何控制并发中大规模层级调用,消息传递。